8 ответов:
тесты на нормальность не делают то, что большинство думает, что они делают. Тест Шапиро, Андерсон Дарлинг и другие являются тестами нулевой гипотезы против предположения о нормальности. Они не должны использоваться для определения того, следует ли использовать обычные статистические процедуры теории. На самом деле они практически не представляют ценности для аналитика данных. При каких условиях мы заинтересованы в отклонении нулевой гипотезы о том, что данные нормально распределены? Я никогда не сталкивался с ситуацией, когда обычный тест правильно. Когда размер выборки мал, даже большие отклонения от нормальности не обнаруживаются, а когда ваш размер выборки велик, даже самое маленькое отклонение от нормальности приведет к отклоненному нулю.
например:
> set.seed(100) > x <- rbinom(15,5,.6) > shapiro.test(x) Shapiro-Wilk normality test data: x W = 0.8816, p-value = 0.0502 > x <- rlnorm(20,0,.4) > shapiro.test(x) Shapiro-Wilk normality test data: x W = 0.9405, p-value = 0.2453Итак, в обоих этих случаях (биномиальные и логнормальные вариации) значение p > 0,05 вызывает отказ отклонить null (что данные нормальны). Означает ли это, что мы должны заключить, что данные являются нормальными? (подсказка: ответ нет.) Отказ отвергнуть-это не то же самое, что принять. Это проверка гипотезы 101.
но как насчет больших размеров выборки? Возьмем случай, когда там распределение очень почти нормально.
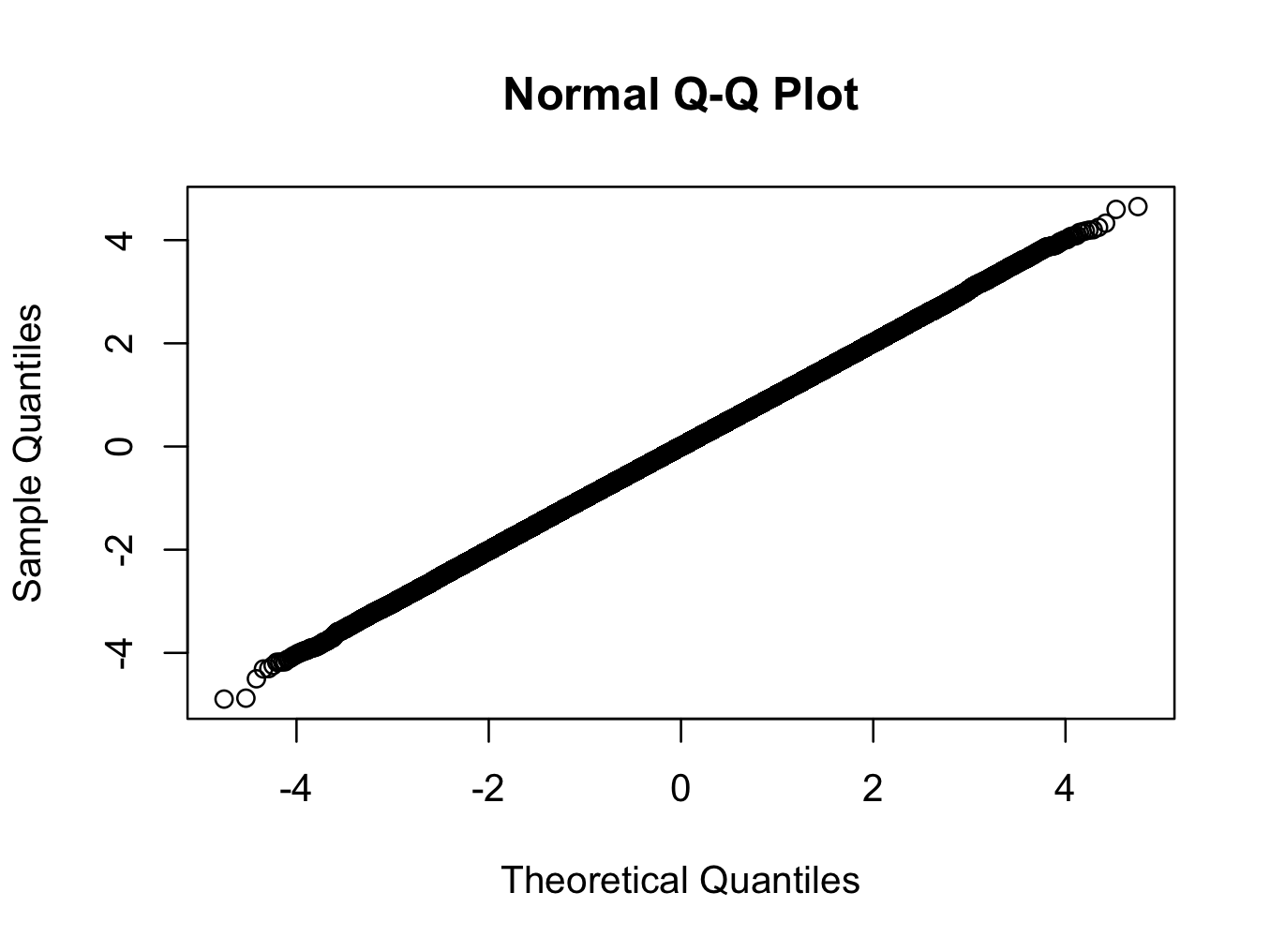
> library(nortest) > x <- rt(500000,200) > ad.test(x) Anderson-Darling normality test data: x A = 1.1003, p-value = 0.006975 > qqnorm(x)
здесь мы используем Т-распределение с 200 степенями свободы. QQ-график показывает, что распределение ближе к нормальному, чем любое распределение, которое вы, вероятно, увидите в реальном мире, но тест отвергает нормальность с очень высокой степенью уверенности.
означает ли значительный тест против нормальности, что мы не должны использовать нормальную статистику теории в этом случае? (еще одна подсказка: ответ-нет :) )
Я также очень рекомендую
SnowsPenultimateNormalityTestнаTeachingDemosпакета. Элемент документация функции - это гораздо полезнее для Вас, чем сам тест, хотя. Внимательно прочитайте его перед использованием теста.
SnowsPenultimateNormalityTestконечно имеет свои достоинства, но вы также можете посмотреть наqqnorm.X <- rlnorm(100) qqnorm(X) qqnorm(rnorm(100))
рассмотрите возможность использования функции
shapiro.test, который выполняет тест Шапиро-Уилкса на нормальность. Я был счастлив с ним.
когда вы выполняете тест, у вас всегда есть вероятность отклонить нулевую гипотезу, когда она истинна.
смотрите следующий код R:
p=function(n){ x=rnorm(n,0,1) s=shapiro.test(x) s$p.value } rep1=replicate(1000,p(5)) rep2=replicate(1000,p(100)) plot(density(rep1)) lines(density(rep2),col="blue") abline(v=0.05,lty=3)график показывает, что независимо от того, есть ли у вас размер выборки маленький или большой, в 5% случаев у вас есть шанс отклонить нулевую гипотезу, когда она истинна (ошибка типа I)
в дополнение к qqplots и тесту Шапиро-Уилка могут быть полезны следующие методы.
качественные:
- гистограмма по сравнению с нормальной
- cdf по сравнению с нормальным
- ggdensity plot
- ggqqplot
количественные:
в квалификационные методы могут быть получены с использованием следующих в R:
library("ggpubr") library("car") h <- hist(data, breaks = 10, density = 10, col = "darkgray") xfit <- seq(min(data), max(data), length = 40) yfit <- dnorm(xfit, mean = mean(data), sd = sd(data)) yfit <- yfit * diff(h$mids[1:2]) * length(data) lines(xfit, yfit, col = "black", lwd = 2) plot(ecdf(data), main="CDF") lines(ecdf(rnorm(10000)),col="red") ggdensity(data) ggqqplot(data)слово предостережения-не применяйте слепо тесты. Имея твердое понимание статистики поможет вам понять, когда использовать какие тесты и важность предположений в тестировании гипотез.
Comments