Создание графика вызовов для файла с clang
Есть ли способ создать график вызовов с clang, который может разумно поместиться на странице?
То есть дано:
#include<iostream>
using namespace std;
int main()
{
int a;
cin>>a;
cout<<a;
cout<<a;
return 0;
}
I текущий get 
С помощью:
$ clang++ main.cpp -S -emit-llvm -o - |
opt -analyze -std-link-opts -dot-callgraph
$ cat callgraph.dot | c++filt |
sed 's,>,\>,g; s,-\>,->,g; s,<,\<,g' |
gawk '/external node/{id=$1}$1!=id' | dot -Tpng -ocallgraph.png
(что кажется большим усилием, чтобы сделать что-то, что я не ожидал, что будет так трудно). Я хотел бы получить что-то более разумное на горизонтальной оси. Unflatten, кажется, не оказывает никакого влияния (по крайней мере, на этот файл, на другие файлы он, кажется, имеет минимальное влияние). эффект).
Есть ли способ гарантировать, что созданный файл png может удобно поместиться на странице (любого стандартного размера)?
Примечание: код для вышеизложенного взят из генерация вызывающего графа для кода C++
Update: Setting page= "8.5, 11" дает следующее:
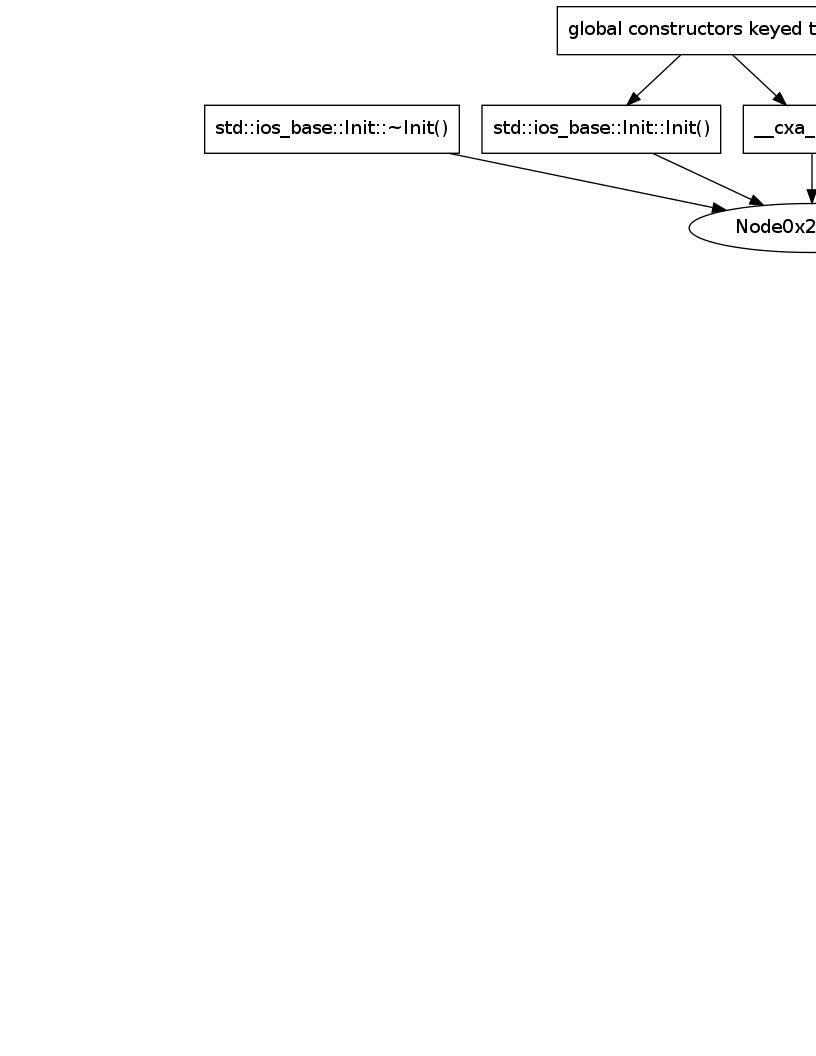
1 ответ:
Я думаю, что первое, что нужно сделать, - это установить направление графика от Нижнего к верхнему ранжированию по умолчанию слева направо, вставив:
rankdir=LR;... в верхней части файла
.dot, после первого файла{. Это должно ориентировать график слева направо и тем самым сделать его гораздо более компактным для случая, подобного этому, который имеет длинные метки узлов. Точно, как это может быть сделано, будет зависеть от форматаcallgraph.dot, но, предполагая, что это выглядит примерно так:digraph G { node [shape=rectangle]; ...... затем что-то вроде:
sed 's/digraph G {/digraph G { \n rankdir=LR;/'... сделает свою работу.
Другой подход, который я использовал в прошлом, заключается в том, чтобы вставить фиктивные узлы в ребра, чтобы уменьшить число узлов, которые имеют одинаковый ранг (и поэтому будут нарисованы в одной строке (сrankdir=TB, что является значением по умолчанию) или столбце (сrankdir=LR). Это легко сделать при написании файлов.dotвручную,но сложнее написать сценарий.Если вы хотите написать сценарий вставки дополнительных узлов в некоторые ребра для распространения узлов, которые обычно это один и тот же ранг по нескольким рангам, вы можете сделать это, запустив
dot -Tplainдля вывода простого текстового файла*, который включает (среди прочего) список узлов с координатами X и Y центра каждого узла. Затем вы можете использоватьgawkдля чтения этого списка, найти любую большую группу узлов с одной и той же координатой X (Еслиrankdir=TB) или Y (еслиrankdir=LR), а затем обработать исходный файл.dot, чтобы вставить дополнительный пустой узел перед (скажем) половиной узлов в этой группе, так что группа была разбросана по двум рядам, а не по одному. Но у меня не было возможности сделать это самому.*см. Эмден Gansner, Элефтериос Koutsofios и Стивен Севера (2006) рисования графиков с точкой, приложение Б.
EDIT: как автоматически вставлять дополнительные узлы.
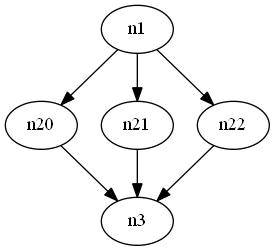
Задается файл
.dottest1.dotследующим образом:digraph G { n1 -> n20 n1 -> n21 n1 -> n22 n20 -> n3 n21 -> n3 n22 -> n3 }... который производит показанный график.
... запуск
dot -Tplain test1.dot >test1.plainдает файлtest1.plain:Таким образом, теперь мы можем обрабатывать оба файла вместе. Я буду использовать Python для этого, потому что это немного легче сделать в Python, чем в Awk. Ради этого примера я ограничил число узлов в ранге до 2 и использовал ранг, определенный по умолчанию снизу вверх, а не слева направо, как я предлагал выше. Я не знаю точно, какой файлgraph 1 2.75 2.5 node n1 1.375 2.25 0.75 0.5 n1 solid ellipse black lightgrey node n20 0.375 1.25 0.75 0.5 n20 solid ellipse black lightgrey node n21 1.375 1.25 0.75 0.5 n21 solid ellipse black lightgrey node n22 2.375 1.25 0.75 0.5 n22 solid ellipse black lightgrey node n3 1.375 0.25 0.75 0.5 n3 solid ellipse black lightgrey edge n1 n20 4 1.1726 2.0394 1.0313 1.9019 0.83995 1.7159 0.68013 1.5605 solid black edge n1 n21 4 1.375 1.9958 1.375 1.8886 1.375 1.7599 1.375 1.6405 solid black edge n1 n22 4 1.5774 2.0394 1.7187 1.9019 1.9101 1.7159 2.0699 1.5605 solid black edge n20 n3 4 0.57736 1.0394 0.71875 0.90191 0.91005 0.71592 1.0699 0.56054 solid black edge n21 n3 4 1.375 0.99579 1.375 0.88865 1.375 0.7599 1.375 0.64045 solid black edge n22 n3 4 2.1726 1.0394 2.0313 0.90191 1.8399 0.71592 1.6801 0.56054 solid black stop.dotвыводитсяclang, поэтому может возникнуть необходимость изменить этот пример. немного, чтобы принять это во внимание.import sys,re; plain = open(sys.argv[2]) nodesInRank = {} for line in plain: x = line.split() rankloc = 3 # rank is in the y column for the vertical case. # Change this to rankloc = 2 for the horizontal case if len(x) > 0 and x[0] == "node": nodesInRank[x[rankloc]] = nodesInRank.get(x[rankloc],[]) + [x[1]] maxNodesInRank = 2 dummies = set() for n in nodesInRank.values(): if len(n) > maxNodesInRank: dummies = dummies | set(n[:len(n)//2]) dot = open(sys.argv[1]) for line in dot: line = line.rstrip() line2 = "" for d in dummies: m = "-> +%s" % (d) if re.search(m,line): line = re.sub(m,"-> dummy_%s [dir = none]\n dummy_%s -> %s" % (d,d,d),line) line2 = '\tdummy_%s [shape=none, width=0, height=0, label=""];' % (d) print (line) if len(line2) > 0: print (line2)Учитывая этот скрипт Python, который я назвал
breakrank.py, теперь я могу запустить его как:python breakrank.py test1.dot test1.plain >test_dummy.dot... что ставит следующее в
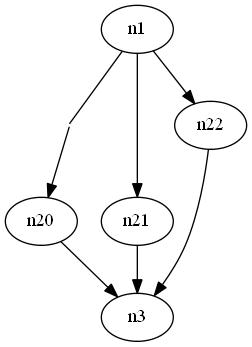
test_dummy.dot:digraph G { n1 -> dummy_n20 [dir = none] dummy_n20 -> n20 dummy_n20 [shape=none, width=0, height=0, label=""]; n1 -> n21 n1 -> n22 n20 -> n3 n21 -> n3 n22 -> n3 }Если мы пропустим это через
dot, то получим:
... что дает нам то, что мы хотим, я думаю.
Comments