7 ответов:
сканирование индекса - это когда SQL server считывает весь индекс в поисках совпадений - время, которое это занимает, пропорционально размеру индекса.
поиск индекса-это когда SQL server использует структуру b-дерева индекса для прямого поиска соответствующих записей (см. http://mattfleming.com/node/192 для идеи о том, как это работает) - время, затраченное только пропорционально количеству совпадающих записей.
- вообще индекс искать есть предпочтительнее сканирования индекса (когда число совпадающих записей значительно меньше общего числа записей), так как время, необходимое для выполнения поиска индекса, является постоянным независимо от общего числа записей в вашей таблице.
- однако обратите внимание, что в некоторых ситуациях сканирование индекса может быть быстрее, чем поиск индекса (иногда значительно быстрее) - обычно, когда таблица очень мала, или когда большой процент записей соответствует предикат.
основное правило, которому нужно следовать, - это сканирование плохо, поиски хороши.
Index Scan
когда SQL Server выполняет сканирование, он загружает объект, который он хочет прочитать с диска в память, а затем читает этот объект сверху вниз, ища записи, которые ему нужны.
Index Seek
когда SQL Server выполняет поиск, он знает, где в индексе будут данные, поэтому он загружает индекс с диска, переходит непосредственно к нужной части индекса и считывает туда, где заканчиваются нужные данные. Очевидно, что это гораздо более эффективная операция, чем сканирование, поскольку SQL уже знает, где находятся данные, которые он ищет.
как я могу изменить план выполнения, чтобы использовать поиск вместо сканирования?
когда SQL Server ищет ваши данные, вероятно, одна из самых больших вещей, которая заставит SQL Server переключиться с поиска на сканирование, - это когда некоторые из столбцов, которые вы ищете, не включены в индекс, который вы хотите использовать. Чаще всего это приведет к тому, что SQL Server вернется к проверке кластеризованного индекса, поскольку кластеризованный индекс содержит все столбцы в таблице. Это одна из самых больших причин (по крайней мере, на мой взгляд), что теперь у нас есть возможность включать столбцы в индекс, не добавляя эти столбцы в индексированные столбцы индекса. Путем включения дополнительных столбцов в индекс мы увеличиваем размер индекс, но мы разрешаем SQL Server читать индекс, не возвращаясь к кластеризованному индексу или к таблице, чтобы получить эти значения.
ссылки
сведения о специфике каждого из этих операторов в рамках плана выполнения SQL Server см. В разделе....
сканирование против поиска
Сканирование Индекса:
поскольку сканирование затрагивает каждую строку в таблице, независимо от того, соответствует ли она требованиям, стоимость пропорциональна общему количеству строк в таблице. Таким образом, сканирование является эффективной стратегией, если таблица мала или если большинство строк соответствует предикату.
Ищут:
так как искать только прикосновения строки, которые квалифицируют, и страницы, содержащие эти квалифицирующие строки, стоимость пропорциональна количеству квалифицирующих строк и страниц, а не общему количеству строк в таблице.
Index Scan это не что иное, как сканирование на страницах данных с первой страницы до последней страницы. Если в таблице есть индекс и если запрос касается большего объема данных, это означает, что запрос извлекает более 50 или 90 процентов данных, а затем оптимизатор будет просто сканировать все страницы данных, чтобы получить строки данных. Если индекс отсутствует, то в плане выполнения может отображаться проверка таблицы (Index Scan).
ищет обычно предпочтительны для высокоселективных запросов. Это означает, что запрос просто запрашивает меньшее количество строк или просто извлекает остальные 10 (некоторые документы говорят 15 процентов) строк таблицы.
в общем оптимизатор запросов пытается использовать Поиск индекса, что означает, что оптимизатор нашел полезный индекс для извлечения набора записей. Но если это невозможно сделать либо из-за отсутствия индекса, либо из-за отсутствия полезных индексов в таблице, то SQL Server должен сканировать все записи, удовлетворяющие условию запроса.
разница между сканированием и искать?
сканирование возвращает всю таблицу или индекс. Поиск эффективно возвращает строки из одного или нескольких диапазонов индекса на основе предикат. Например, рассмотрим следующий запрос:
select OrderDate from Orders where OrderKey = 2сканирование
при сканировании мы читаем каждую строку в таблице orders, оцениваем предикат "where OrderKey = 2" и, если предикат истинен (т. е. если строка квалифицируется), возвращаем строку. В этом случае мы называем предикат "остаточным" предикатом. Чтобы максимизировать производительность, по возможности мы оцениваем остаточный предикат в сканировании. Однако, если предикат слишком дорого, мы можем оценить его в отдельном итераторе фильтра. Остаточный предикат появляется в текстовом showplan с ключевым словом WHERE или в XML showplan с тегом.
вот текст showplan (слегка отредактированный для краткости) для этого запроса с помощью сканирования:
|–Table Scan (OBJECT: ([ORDERS]), где: ([ORDERKEY]=(2)))
следующий рисунок иллюстрирует сканирование:
так как сканирование касается каждого строка в таблице независимо от того, соответствует ли она требованиям, стоимость пропорциональна общему количеству строк в таблице. Таким образом, сканирование является эффективной стратегией, если таблица мала или если большинство строк соответствует предикату. Однако, если таблица большая и если большинство строк не соответствует требованиям, мы касаемся гораздо большего количества страниц и строк и выполняем гораздо больше операций ввода-вывода, чем это необходимо.
искать
возвращаясь к примеру, если у нас есть индекс на OrderKey, a поиск может быть лучшим планом. При поиске мы используем индекс для перехода непосредственно к тем строкам, которые удовлетворяют предикату. В этом случае мы ссылаемся на предикат как на предикат "seek". В большинстве случаев нам не нужно повторно оценивать предикат поиска как остаточный предикат; индекс гарантирует, что поиск возвращает только строки, которые соответствуют требованиям. Предикат seek появляется в текстовом showplan с ключевым словом SEEK или в XML showplan с тегом.
вот текст showplan для тот же запрос с помощью поиска:
/ - Index Seek (OBJECT: ([ORDERS].[OKEY_IDX]), SEEK: ([ORDERKEY]=(2)) ORDERED FORWARD)
следующий рисунок иллюстрирует искать:
поскольку поиск затрагивает только строки, которые соответствуют требованиям, и страницы, содержащие эти квалифицирующие строки, стоимость пропорциональна количеству квалифицирующих строк и страниц, а не общему количеству строк в таблице. Таким образом, поиск, как правило, больше эффективная стратегия, если у нас есть высокоселективный предикат поиска; то есть, если у нас есть предикат поиска, который устраняет большую часть таблицы.
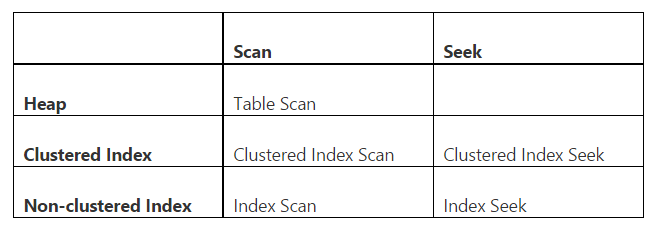
заметка о showplan
в showplan мы различаем сканирование и поиск, а также сканирование на кучах (объект без индекса), кластеризованные индексы и некластеризованные индексы. В следующей таблице показаны все допустимые комбинации:
https://blogs.msdn.microsoft.com/craigfr/tag/scans-and-seeks/
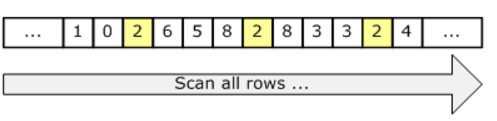
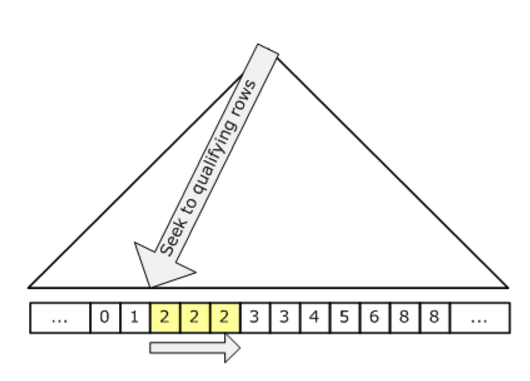
при сканировании индекса все строки в индексе сканируются для поиска соответствующей строки. Это может быть эффективно для небольших таблиц. При поиске индекса ему нужно только коснуться строк, которые действительно соответствуют критериям, и поэтому, как правило, более эффективны
короткий ответ:
сканирование индекса: коснитесь всех строк, но определенных столбцов.
Поиск индекса: коснитесь определенных строк и определенных столбцов.
сканирование коснется каждой строки в таблице, даже если то, что вы после или нет
сканирование смотрит только на строки, которые вы ищете.
Поиск всегда лучше иметь, чем сканирование, поскольку они более эффективны в том, как он ищет данные.
хорошее объяснение можно найти здесь
сканирование индекса происходит, когда определение индекса не может найти в одной строке для удовлетворения предикатов поиска. В этом случае SQL Server должен сканировать несколько страниц найти ряд строк, удовлетворяющих предикатам поиска.
в случае поиска индекса SQL Server находит одну строку, соответствующую предикатам поиска, используя индекс определение.
индекс ищет лучше и эффективнее.
Comments