Скорость вставки SQLite замедляется по мере увеличения количества записей из-за индекса
исходный вопрос
фон
хорошо известно, что SQLite должен быть настроен для достижения скорости вставки порядка 50k вставок / С. Здесь есть много вопросов относительно медленных скоростей вставки и множество советов и тестов.
также утверждает, что SQLite может обрабатывать большие объемы данных, с отчетами 50 + GB не вызывая никаких проблем с правом настройки.
я следовал советам здесь и в других местах для достижения этих скоростей, и я доволен 35k-45k вставками/С. проблема у меня есть в том, что все тесты демонстрируют только быстрые скорости вставки с записями скорость вставки, кажется, обратно пропорциональна размеру таблицы.
вопрос
мой вариант использования требует хранения от 500 м до 1B кортежей ([x_id, y_id, z_id]) в течение нескольких лет (1м строк / день) в таблице ссылок. Все значения представляют собой целочисленные идентификаторы от 1 до 2 000 000. Существует один индекс на z_id.
производительность отлично подходит для первых 10 м строк, ~35k вставок/с, но к тому времени, когда таблица имеет ~20 м строк, производительность начинает страдать. Сейчас я вижу около 100 вставок/С.
размер таблицы не особенно большой. С 20м строк, размер на диске около 500 МБ.
проект написан на Perl.
вопрос
Is это реальность больших таблиц в SQLite или есть какие-то секреты сохранение высокие тарифы вставки для таблиц с строками > 10m?
известны обходные пути, которые я хотел бы избежать если это возможно
отбросьте индекс, добавьте записи и переиндексируйте: это прекрасно, как обходной путь, но не работает, когда БД все еще должен использоваться во время обновлений. Он не будет работать, чтобы сделать базу данных недоступной для x минуты / день
разбить таблицу на более мелкие подтаблиц / файлы: это будет работать в краткосрочной перспективе, а я уже экспериментировал с ней. Проблема в том, что мне нужно иметь возможность извлекать данные из всей истории при запросе, что означает, что в конечном итоге я достигну предела вложения таблицы 62. Прикрепление, сбор результатов во временной таблице и отсоединение сотни раз за запрос, похоже, много работы и накладных расходов, но я попробую, если их нет другие альтернативные варианты.
SetSQLITE_FCNTL_CHUNK_SIZE: я не знаю C (?!), поэтому я бы предпочел не изучать его, чтобы сделать это. Однако я не вижу способа установить этот параметр с помощью Perl.
обновление
после Тим что индекс вызывает все больше
медленное время вставки, несмотря на утверждения SQLite о том, что он способен
при обработке больших наборов данных я выполнил сравнение с эталоном следующий
настройки:
- вставить строки: 14 млн.
- совершал размер пакета: 50 000 записей
cache_sizepragma: 10,000
page_sizepragma: 4,096
temp_storepragma:
journal_modepragma:удалить
synchronouspragma: выкл
в моем проекте, как и в результатах тестирования ниже, создается временная таблица на основе файлов и встроенная поддержка SQLite
для импорта данных CSV используется. Затем прикрепляется временная таблица
в получающую базу данных и наборы из 50 000 строк вставляются
insert-select заявление. Поэтому время вставки не отражает
file to database вставить раз, но скорее таблицы к таблице вставить
скорость. Принимая CSV время импорта во внимание позволит снизить скорость
на 25-50% (очень грубая оценка, это не займет много времени для импорта
Данные CSV).
очевидно, что наличие индекса вызывает замедление скорости вставки при увеличении размера таблицы.
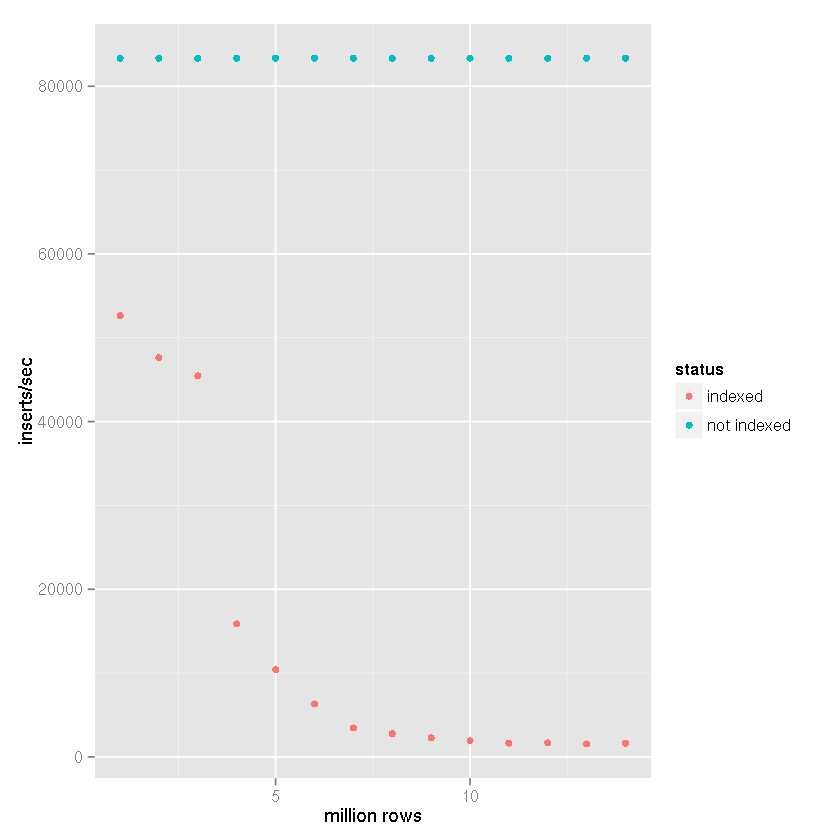
из приведенных выше данных совершенно ясно, что правильный ответ может быть назначен ответ Тима а не утверждения, что SQLite просто не может справиться с этим. Очевидно, это можете ручки большие наборы данных если индексирование этого набора данных не является частью вашего варианта использования. Я использую SQLite только для этого, в качестве бэкэнда для системы ведения журнала, на некоторое время, что делает не нужно индексировать, поэтому я был очень удивлен замедлением, которое я испытал.
вывод
если кто-то хочет хранить большое количество данных с помощью SQLite и его индексировать, с помощью Черепков может быть ответ. В конце концов я решил использовать первые три символа MD5 hash уникальный столбец в z определить назначение одной из 4096 баз данных. Поскольку мой вариант использования в основном является архивным по своей природе, схема не изменится, и запросы никогда не потребуют обхода осколков. Существует ограничение на размер базы данных, так как очень старые данные будут уменьшены и в конечном итоге отброшены, поэтому эта комбинация параметров sharding, pragma и даже некоторых deнормализация дает мне хороший баланс, который будет, основываясь на приведенном выше бенчмаркинге, поддерживать скорость вставки не менее 10k вставок / сек.
1 ответ:
Если ваше требование состоит в том, чтобы найти конкретный z_id и связанные с ним x_ids и y_ids (в отличие от быстрого выбора диапазона z_ids), вы можете заглянуть в неиндексированную хэш-таблицу вложенной реляционной БД, которая позволит вам мгновенно найти свой путь к конкретному z_id, чтобы получить его y_ids и x_ids-без накладных расходов на индексирование и сопутствующего снижения производительности во время вставок по мере роста индекса. Для того, чтобы избежать слипания ака ведро столкновений, выберите ключ алгоритм хэширования, который ставит наибольший вес на цифры z_id с наибольшей вариацией (взвешенный справа).
P. S. В базе данных, которая используется B-дерево может показаться на первый взгляд быстрее, чем БД, который использует линейное хеширование, говорят, но выбирать его производительность будет находиться на одном уровне с линейной хэш в исполнении B-дерево начинает деградировать.
P. P. S. Чтобы ответить на вопрос kawing-chiu: основная особенность здесь заключается в том, что такая база данных опирается на так называемые "разреженные" таблицы в физическое расположение записи определяется алгоритмом хэширования, который принимает ключ записи в качестве входных данных. Этот подход позволяет искать напрямую к месту записи в таблице без посредника индекса. Поскольку нет необходимости пересекать индексы или перебалансировать индексы, время вставки остается постоянным, поскольку таблица становится более плотно заполненной. С b-деревом, напротив, время вставки ухудшается по мере роста дерева индекса. Применения ОЛТП с большое количество параллельных вставок может извлечь выгоду из такого подхода с разреженной таблицей. Записи разбросаны по всей таблице. Недостатком записей, разбросанных по" тундре " разреженной таблицы, является то, что сбор больших наборов записей, которые имеют общее значение, например почтовый индекс, может быть медленнее. Хэшированный подход к разреженной таблице оптимизирован для вставки и извлечения отдельных записей, а также для извлечения сетей связанных записей, не большие наборы записей которые имеют некоторое общее значение поля.
вложенная реляционная база данных-это та, которая позволяет кортежи внутри столбец строки.
Comments