Сравните две спектрограммы, чтобы найти смещение, где они соответствуют алгоритму
Я записываю ежедневную 2-минутную радиопередачу из интернета. Там всегда один и тот же начальный и конечный звон. Поскольку точное время радиопередачи может варьироваться от более или менее 6 минут, мне приходится записывать около 15 минут радио.
Я хочу определить точное время, когда эти джинглы находятся в записи 15 минут, чтобы я мог извлечь ту часть звука, которую я хочу.
Я уже запустил приложение C#, где я декодирую MP3 в данные PCM и преобразую данные PCM в a спектрограмма на основе http://www.codeproject.com/KB/audio-video/SoundCatcher.aspx
Я попытался использовать алгоритм перекрестной корреляции на данных PCM, но алгоритм очень медленный около 6 минут с шагом 10 мс и в некоторых случаях он не может найти время начала звона.
Есть идеи алгоритмов для сравнения двух спектрограмм на соответствие? Или лучший способ найти время начала этого звона?
Спасибо,
Обновление, извините за задержка
Во-первых, спасибо всем анвсерам, большинство из которых были релевантными и интересными идеями.
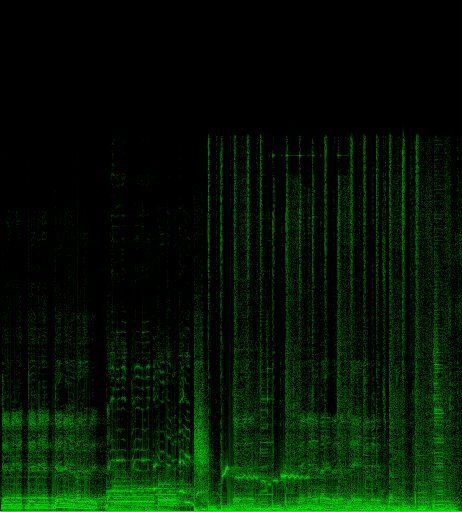
Я попытался реализовать алгоритм Шазама, предложенный Фонзо. Но обнаружить пики на спектрограмме не удалось. Вот три спектрограммы стартового звона с трех разных пластинок. Я пытался AForge.NET с помощью фильтра blob (но он не смог идентифицировать пики), чтобы размыть изображение и проверить разницу в высоте, свертка Лапласа, анализ наклона, чтобы обнаружить серия вертикальных баров (но было слишком много ложных срабатываний)...
В то же время я попробовал алгоритм Хоу, предложенный Дэйвом Аароном Смитом. Где я вычисляю среднеквадратичное значение каждого столбца. Да, да, каждый столбец, это O (N*M), но M
Я мог бы пойти с этим решением, но если возможно, я предпочел бы Shazam, потому что это O(N) и вероятно, гораздо быстрее (и круче). Так что у кого-нибудь из вас есть идея алгоритма, чтобы всегда обнаруживать одни и те же точки На этих спектрограммах (не обязательно пики), спасибо за комментарий.


Новое Обновление
Наконец, я пошел с алгоритмом, объясненным выше, я попытался реализовать алгоритм Shazam, но не смог найти правильные пики в спектрограмме, идентифицированные точки, где не постоянны от одного звука. файл к другому. Теоретически алгоритм Шазама является решением для такого рода задач. Алгоритм Хоу, предложенный Дейвом Аароном Смитом, был более стабильным и эффективным. Я разделил около 400 файлов, и только 20 из них не удалось разделить должным образом. Дисковое пространство, когда от 8 ГБ до 1 ГБ.
Спасибо за помощь.
4 ответов:
Интересно, можно ли использовать преобразование Хоу . Вы начнете с каталогизации каждого шага начальной последовательности. Допустим, вы используете 10 мс шагов, а последовательность открытия составляет 50 мс. Вы вычисляете некоторую метрику на каждом шаге и получаете
1 10 1 17 5Теперь пройдите через аудио и проанализируйте каждый шаг 10 мс для одной и той же метрики. Назовем этот массив
have_audioТеперь создайте новый пустой массив такой же длины, как и8 10 8 7 5 1 10 1 17 6 2 10...have_audio. Назовем этоstart_votes. Он будет содержать "голоса" за начало вступительная последовательность. Если вы видите 1, Вы можете быть на 1-м или 3-м шаге открывающей последовательности, поэтому у вас есть 1 голос за открывающую последовательность, начинающуюся 1 шаг назад, и 1 голос за открывающую последовательность, начинающуюся 3 шага назад. Если вы видите 10, у вас есть 1 голос за открывающую последовательность, начинающуюся 2 шага назад, 17 голосов за 4 шага назад и так далее.Так что для этого примера
have_audio, Вашvotesбудет выглядеть как2 0 0 1 0 4 0 0 0 0 0 1 ...У вас много голосов на позиции 6, так что есть хороший шанс открытия последовательность начинается там.
Вы можете улучшить производительность, не утруждая себя анализом всей последовательности открытия. Если последовательность открытия составляет 10 секунд, вы можете просто искать первые 5 секунд.
Здесь есть описание алгоритма, используемого сервисом shazam (который идентифицирует музыку, заданную коротким, возможно, шумным образцом): http://www.ee.columbia.edu/~dpwe / papers / Wang03-shazam. pdf
Из того, что я понял, первое, что нужно сделать, - это выделить пики в спектрограмме (с некоторыми ухищрениями, чтобы обеспечить равномерное покрытие), что даст "констелляцию" пар значений (время;частота) из исходной спектрограммы. После того, как это сделано, образец созвездия сравнивается к созвездию полного трека путем перевода окна длины выборки из начала в конец и подсчета количества коррелированных точек.
Затем в статье описывается техническое решение, которое они нашли, чтобы сделать сравнение быстро даже с огромной коллекцией треков.
Вот хороший пакет python, который делает именно это:
Https://code.google.com/p/py-astm/
Если вы ищете определенный алгоритм, то хорошие термины поиска, которые нужно использовать "accoustic fingerprinting "или"perceptual hashing".
Вот еще один пакет python, который также может быть использован:
Если вы уже знаете последовательность звона, вы можете проанализировать корреляцию с последовательностью, а не перекрестную корреляцию между полными 15-минутными треками.
Чтобы быстро вычислить корреляцию против (короткой) последовательности, я бы предложил использовать фильтр Винера.
Правка: фильтр Винера-это способ найти сигнал в последовательности с шумом. В этом приложении мы рассматриваем все, что "не звенит", как шум (вопрос для читателя: можем ли мы все-таки предположим, что шум белый и не коррелирует?).
( я нашел ссылку, которую искал! Формулы, которые я запомнил, были немного не в порядке, и я удалю их сейчас )
Соответствующая страница-этовинеровская деконволюция . Идея состоит в том, что мы можем определить систему, импульсный отклик которой
Поскольку звон известен, мы можем вычислить его спектр мощностиh(t)имеет ту же форму волны, что и звон, и мы должны найти точку в шумной последовательности, где система получила импульс (т. е. цзинцзе).H(f), и поскольку мы можем предположить, что один звон появляется в записанной последовательности, мы можем сказать, что неизвестный входx(t)имеет форму импульса, плотность мощности которогоS(f)постоянна на каждой частоте.Учитывая вышеизложенные знания, вы можете использовать формулу для получения фильтра" джингл-пасс " (например, только сигналы, имеющие форму джингла, могут проходить), выход которого является самым высоким при воспроизведении джингла.
Comments