Проверьте, имеют ли списки общие элементы в python
Я хочу проверить, если любой предметы в одном списке присутствуют в другом списке. Я могу сделать это просто с помощью кода ниже, но я подозреваю, что для этого может быть функция библиотеки. Если нет, есть ли более подходящие для Python способ достижения того же результата.
In [78]: a = [1, 2, 3, 4, 5]
In [79]: b = [8, 7, 6]
In [80]: c = [8, 7, 6, 5]
In [81]: def lists_overlap(a, b):
....: for i in a:
....: if i in b:
....: return True
....: return False
....:
In [82]: lists_overlap(a, b)
Out[82]: False
In [83]: lists_overlap(a, c)
Out[83]: True
In [84]: def lists_overlap2(a, b):
....: return len(set(a).intersection(set(b))) > 0
....:
9 ответов:
короткий ответ: используйте
not set(a).isdisjoint(b), это вообще самый быстрый.есть четыре распространенных способа проверить, если два списка
aиbподелиться какие-либо предметы. Первый вариант-преобразовать оба в наборы и проверить их пересечение, как таковое:bool(set(a) & set(b)), потому что наборы хранятся с помощью хэш-таблицы в Python, поиск их
O(1)(см. здесь для получения дополнительной информации о сложности операторов в Python). Теоретически, этоO(n+m)в среднемnиmобъекты в спискиaиb. Но 1) он должен сначала создать наборы из списков, которые могут занять не ничтожное количество времени, и 2) он предполагает, что конфликты хэширования редки среди ваших данных.второй способ сделать это-использовать выражение генератора, выполняющее итерацию в списках, например:
any(i in a for i in b)это позволяет осуществлять поиск на месте, поэтому новая память не выделяется промежуточные переменные. Он также выручает на первой находке. но
inоператор всегдаO(n)списки (см. здесь).другой предложенный вариант-это гибридная итерация по одному из списков, преобразование другого в набор и проверка на членство в этом наборе, например:
a = set(a); any(i in a for i in b)четвертый подход заключается в использовании
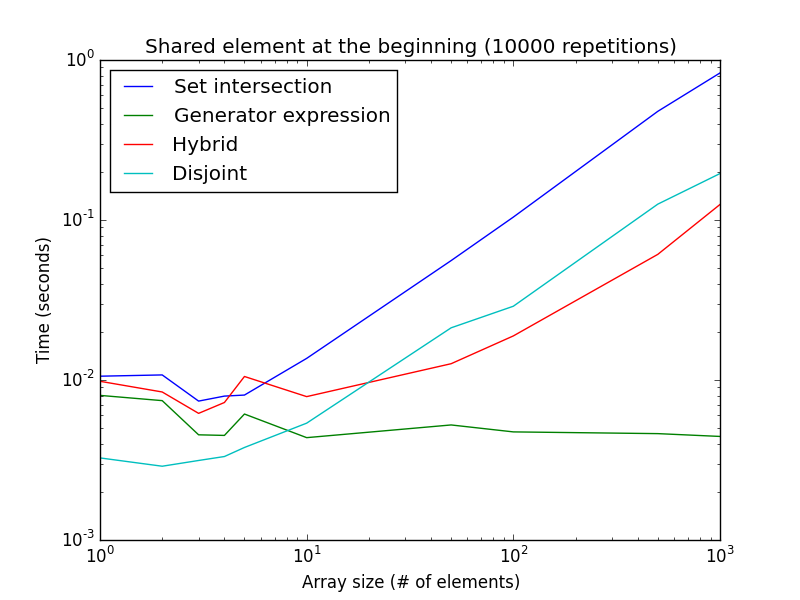
isdisjoint()метод (замороженных) наборов (см. здесь), для пример:not set(a).isdisjoint(b)если элементы, которые вы ищете, находятся в начале массива (например, он отсортирован), выражение генератора предпочтительно, так как метод пересечения множеств должен выделять новую память для промежуточных переменных:
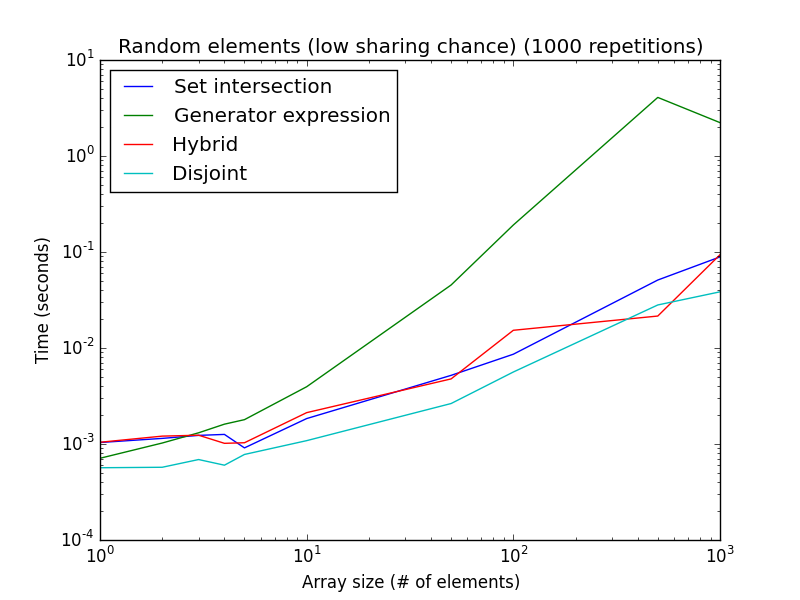
from timeit import timeit >>> timeit('bool(set(a) & set(b))', setup="a=list(range(1000));b=list(range(1000))", number=100000) 26.077727576019242 >>> timeit('any(i in a for i in b)', setup="a=list(range(1000));b=list(range(1000))", number=100000) 0.16220548999262974вот график времени выполнения для этого примера в функции размера списка:
обратите внимание, что обе оси являются логарифмическими. Это представляет собой лучший случай для выражение генератора. Как видно, то
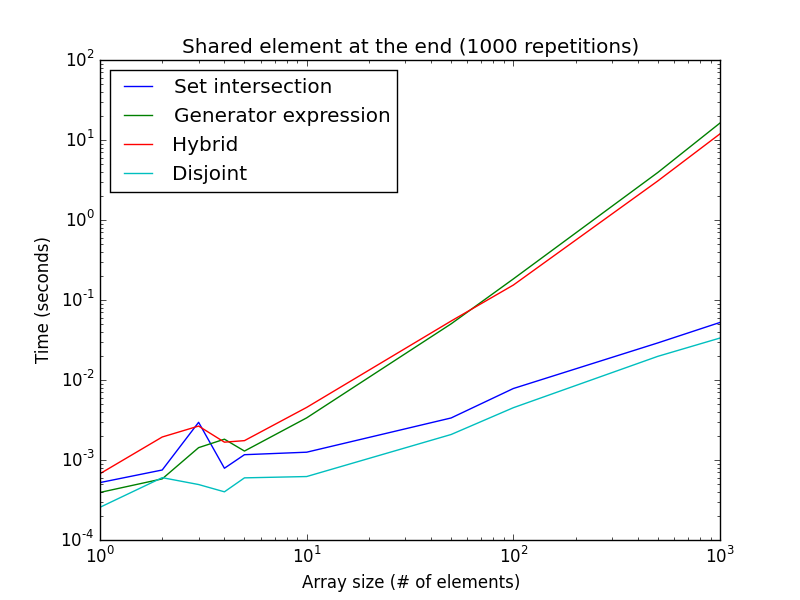
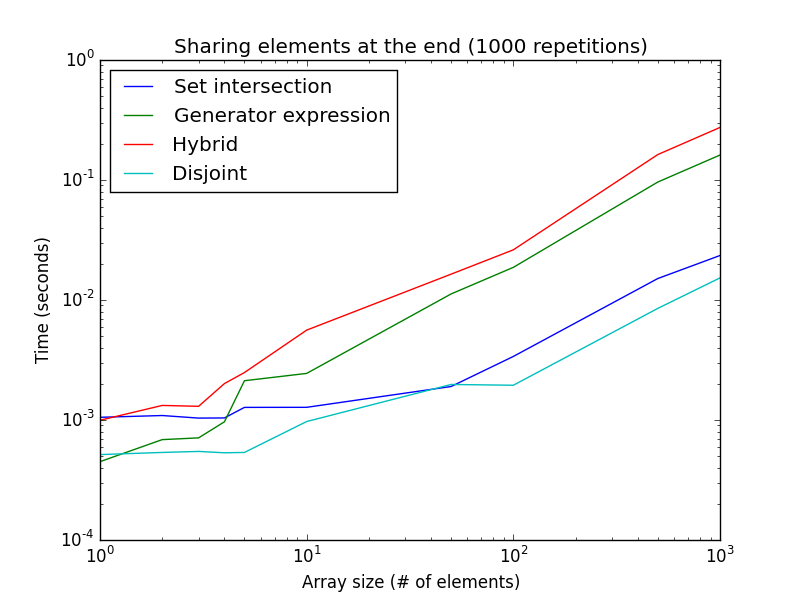
isdisjoint()метод лучше для очень малых размеров списка, в то время как выражение генератора лучше для больших размеров списка.С другой стороны, поскольку поиск начинается с начала для гибридного и генераторного выражения, если общий элемент систематически находится в конце массива (или оба списка не имеют общих значений), подходы к непересекающимся и заданным пересечениям тогда намного быстрее, чем выражение генератора и набор значений. гибридный подход.
>>> timeit('any(i in a for i in b)', setup="a=list(range(1000));b=[x+998 for x in range(999,0,-1)]", number=1000)) 13.739536046981812 >>> timeit('bool(set(a) & set(b))', setup="a=list(range(1000));b=[x+998 for x in range(999,0,-1)]", number=1000)) 0.08102107048034668
интересно отметить, что выражение генератора намного медленнее для больших размеров списка. Это только для 1000 повторений, вместо 100000 для предыдущего рисунка. Эта настройка также хорошо аппроксимируется, когда нет общих элементов, и является лучшим случаем для непересекающихся и заданных подходов к пересечению.
вот два анализа с использованием случайных чисел (вместо фальсификации установки в пользу той или иной техники):
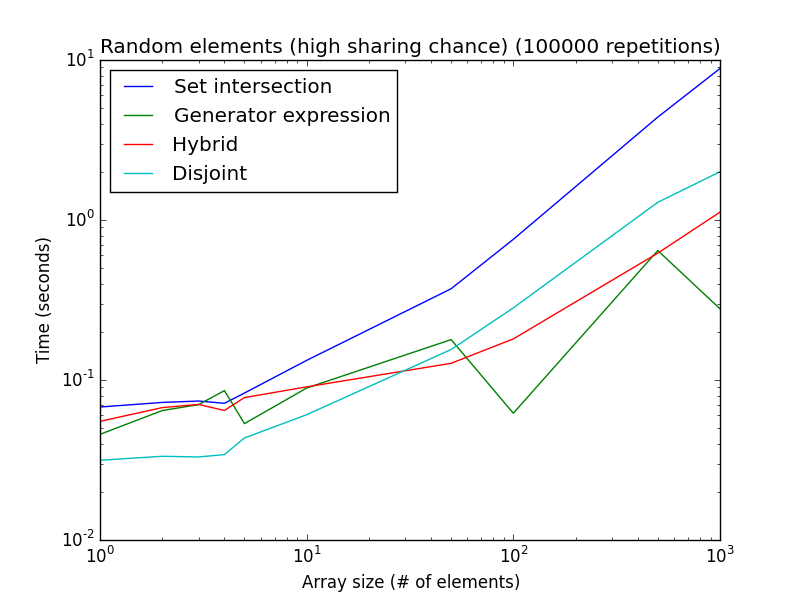
высокая вероятность обмена: элементы случайным образом берутся из
[1, 2*len(a)]. Низкий шанс обмена: элементы случайным образом берутся из[1, 1000*len(a)].до сих пор этот анализ предполагал, что оба списка имеют одинаковый размер. В случае двух списков разных размеров, например
aгораздо меньше,isdisjoint()всегда быстрее:
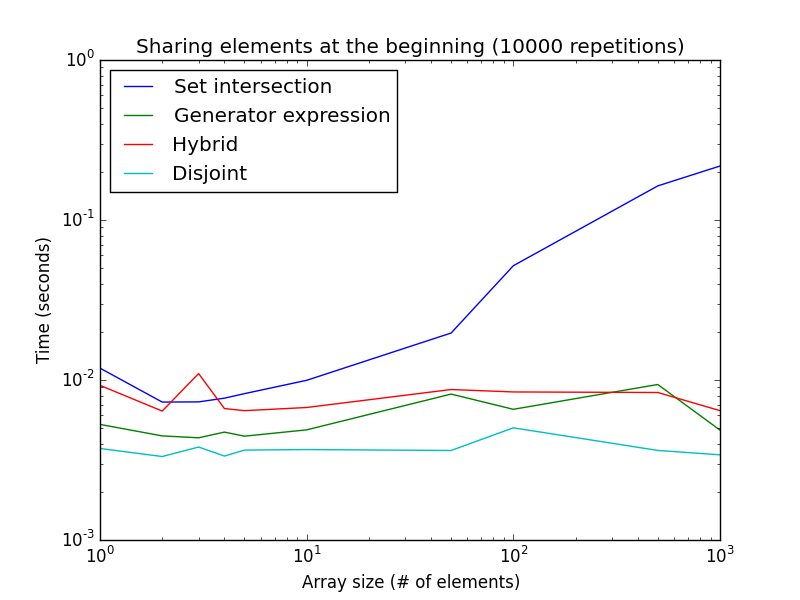
убедитесь, что
aсписок меньше, в противном случае производительность снижается. В этом экспериментеaразмер списка был установлен постоянный к5.в итоге:
- если списки очень малы (not set(a).isdisjoint(b) всегда самый быстрый.
- если элементы в списках отсортированы или имеют регулярную структуру, которую вы можно воспользоваться, генератором выражения
any(i in a for i in b)является самым быстрым на больших размерах списка;
def lists_overlap3(a, b): return bool(set(a) & set(b))Примечание: предполагается, что логический ответ. Если все, что вам нужно, это выражение для использования в
ifзаявление, просто использоватьif set(a) & set(b):
def lists_overlap(a, b): sb = set(b) return any(el in sb for el in a)это асимптотически оптимально (худший случай O (n + m)), и может быть лучше, чем подход пересечения из-за
any's короткое замыкание.например:
lists_overlap([3,4,5], [1,2,3])вернет True, как только он доберется до
3 in sbEDIT: еще одна вариация (благодаря Дэйву Кирби):
def lists_overlap(a, b): sb = set(b) return any(itertools.imap(sb.__contains__, a))это зависит от
imapитератор, который реализован в C, а не понимание генератора. Он также используетsb.__contains__как сопоставление функция. Я не знаю, насколько это влияет на производительность. Это все равно будет короткое замыкание.
в Python 2.6 или более поздней версии вы можете сделать:
return not frozenset(a).isdisjoint(frozenset(b))
вы можете использовать любую встроенную функцию / w выражение генератора:
def list_overlap(a,b): return any(i for i in a if i in b)как указывали Джон И ли, это дает неправильные результаты, когда для каждого я разделял два списка bool(i) == False. Это должно быть:
return any(i in b for i in a)
этот вопрос довольно старый, но я заметил, что в то время как люди спорили наборы против списков, никто не думал использовать их вместе. Следуя примеру Соравукса,
худший случай для списков:
>>> timeit('bool(set(a) & set(b))', setup="a=list(range(10000)); b=[x+9999 for x in range(10000)]", number=100000) 100.91506409645081 >>> timeit('any(i in a for i in b)', setup="a=list(range(10000)); b=[x+9999 for x in range(10000)]", number=100000) 19.746716022491455 >>> timeit('any(i in a for i in b)', setup="a= set(range(10000)); b=[x+9999 for x in range(10000)]", number=100000) 0.092626094818115234и лучший случай для списков:
>>> timeit('bool(set(a) & set(b))', setup="a=list(range(10000)); b=list(range(10000))", number=100000) 154.69790101051331 >>> timeit('any(i in a for i in b)', setup="a=list(range(10000)); b=list(range(10000))", number=100000) 0.082653045654296875 >>> timeit('any(i in a for i in b)', setup="a= set(range(10000)); b=list(range(10000))", number=100000) 0.08434605598449707таким образом, даже быстрее, чем итерация по двум спискам, повторяется, хотя список, чтобы увидеть, находится ли он в наборе, что имеет смысл, поскольку проверка того, находится ли число в наборе, занимает постоянное время при проверке повторение списка занимает время, пропорциональное длине списка.
таким образом, мой вывод заключается в том, что повторите список и проверьте, находится ли он в наборе.
Если вам все равно, что перекрывающийся элемент может быть, вы можете просто проверить
lenОбъединенного списка против списков, объединенных в набор. Если есть перекрывающиеся элементы, то набор будет короче:
len(set(a+b+c))==len(a+b+c)возвращает True, если нет перекрытия.
Я брошу еще один с функциональным стилем программирования:
any(map(lambda x: x in a, b))объяснение:
map(lambda x: x in a, b)возвращает список булевых значений, где элементы
bнаходятся вa. Затем этот список передается вany, который просто возвращаетTrueесли какие-либо элементыTrue.
Comments