В два раза быстрее, чем сдвиг битов?
Я смотрел на источник sorted_containers и был удивлен, увидев эта строка:
self._load, self._twice, self._half = load, load * 2, load >> 1
здесь load - целое число. Зачем использовать сдвиг битов в одном месте и умножение в другом? Кажется разумным, что сдвиг битов может быть быстрее, чем целочисленное деление на 2, но почему бы не заменить умножение на сдвиг? Я сравнил следующие случаи:
- (раз, деление)
- (сдвиг, shift)
- (раз, смена)
- (сдвиг, разрыв)
и обнаружил, что #3 последовательно быстрее, чем другие альтернативы:
# self._load, self._twice, self._half = load, load * 2, load >> 1
import random
import timeit
import pandas as pd
x = random.randint(10 ** 3, 10 ** 6)
def test_naive():
a, b, c = x, 2 * x, x // 2
def test_shift():
a, b, c = x, x << 1, x >> 1
def test_mixed():
a, b, c = x, x * 2, x >> 1
def test_mixed_swaped():
a, b, c = x, x << 1, x // 2
def observe(k):
print(k)
return {
'naive': timeit.timeit(test_naive),
'shift': timeit.timeit(test_shift),
'mixed': timeit.timeit(test_mixed),
'mixed_swapped': timeit.timeit(test_mixed_swaped),
}
def get_observations():
return pd.DataFrame([observe(k) for k in range(100)])
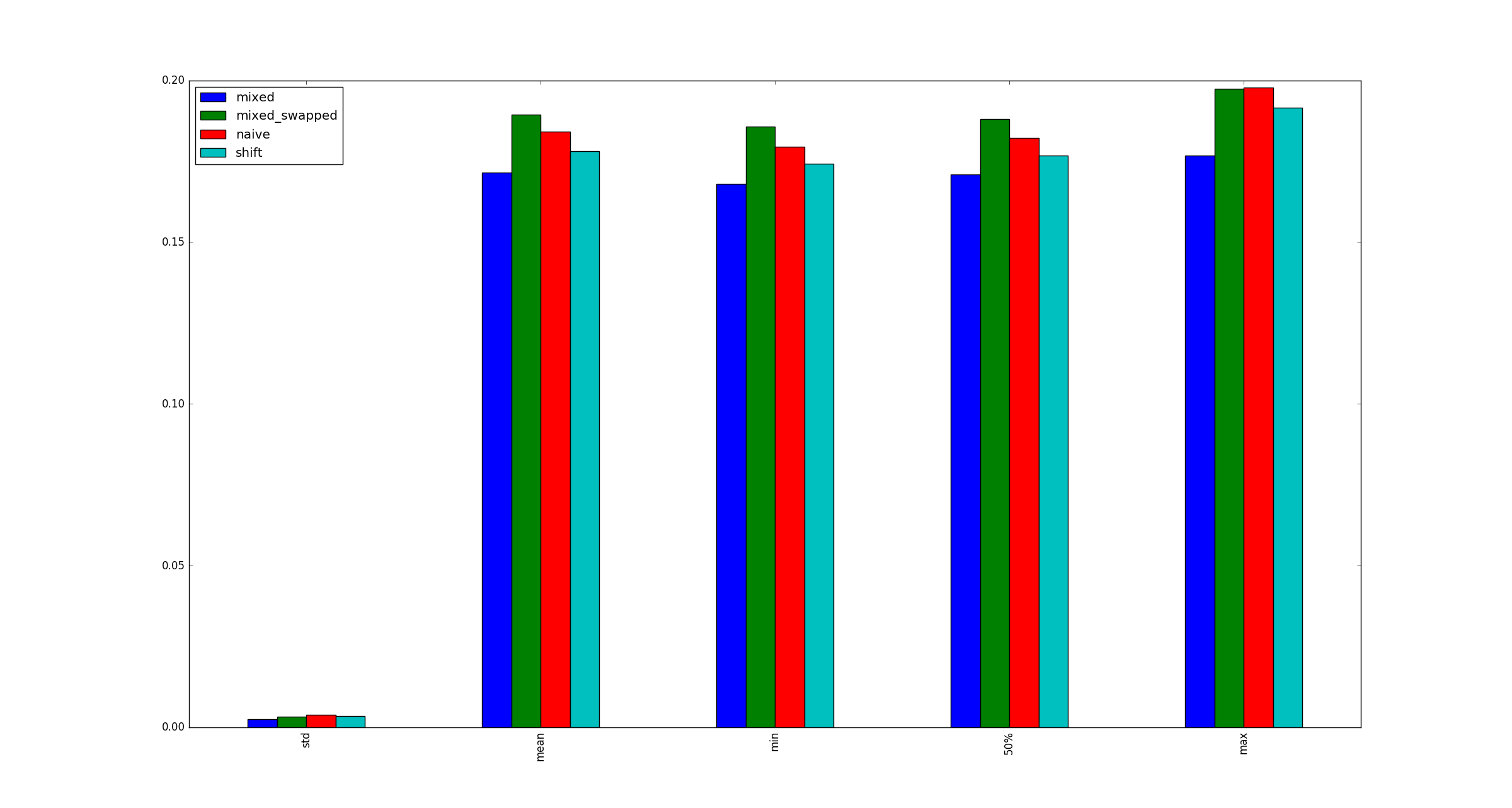
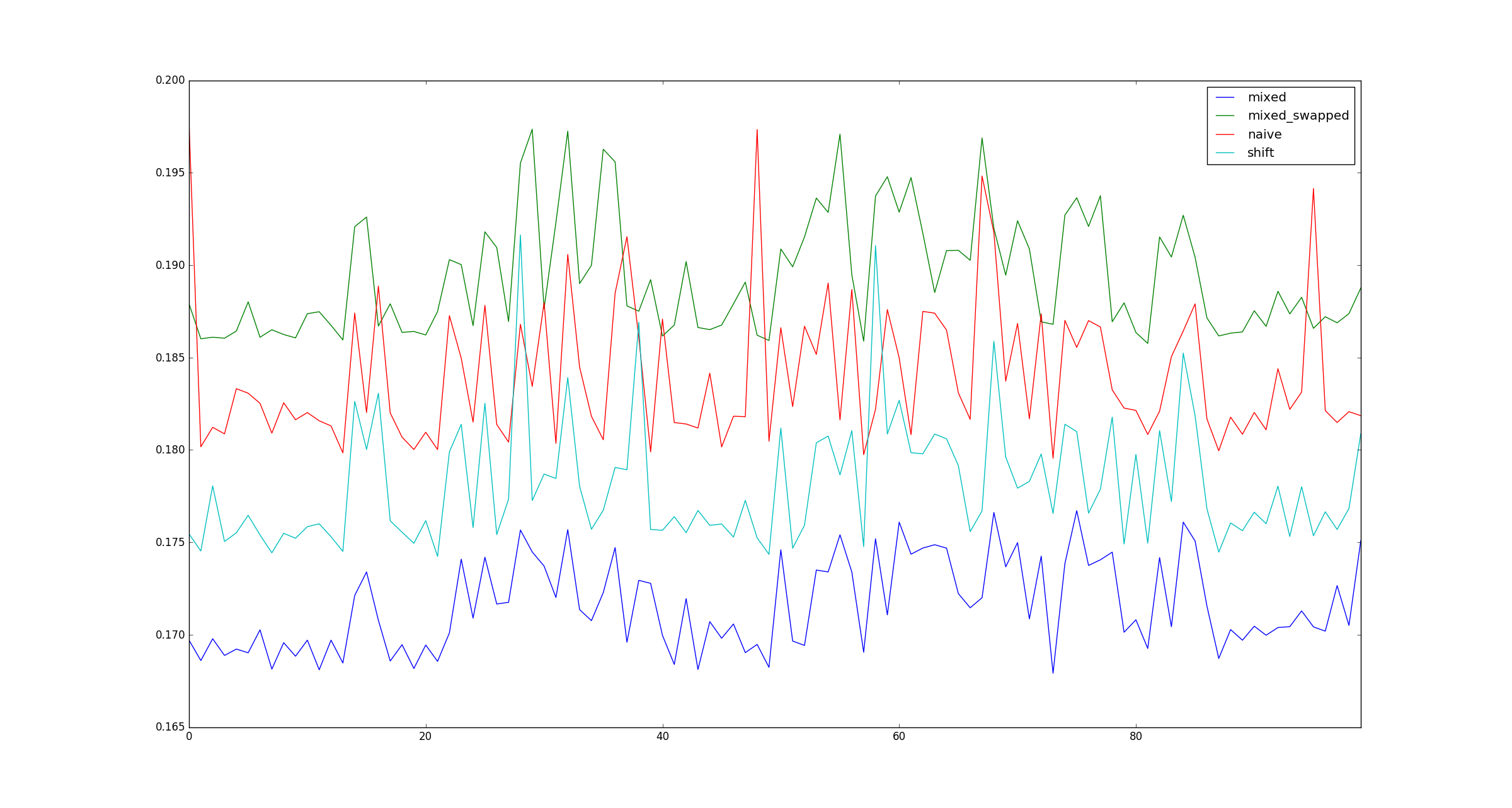
вопрос:
мой тест действителен? Если да, то почему (умножение, сдвиг) быстрее, чем (сдвиг, сдвиг)?
Я запускаю Python 3.5 на Ubuntu 14.04.
Edit
выше приводится исходная постановка вопроса. Дэн Гетц дает отличное объяснение в своем ответе.
для полноты картины, вот примеры иллюстраций для больших x когда оптимизация умножения не применяется.
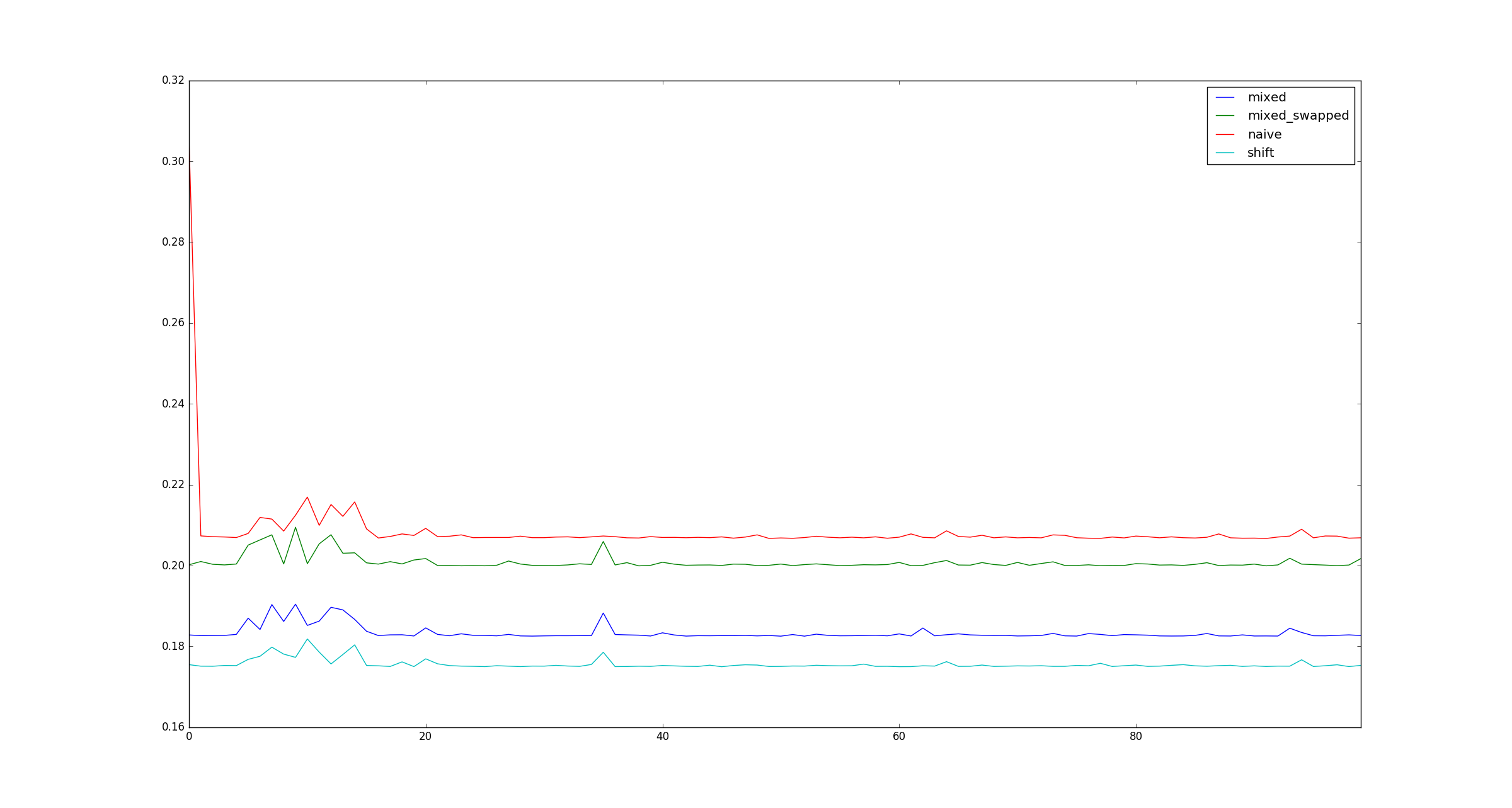
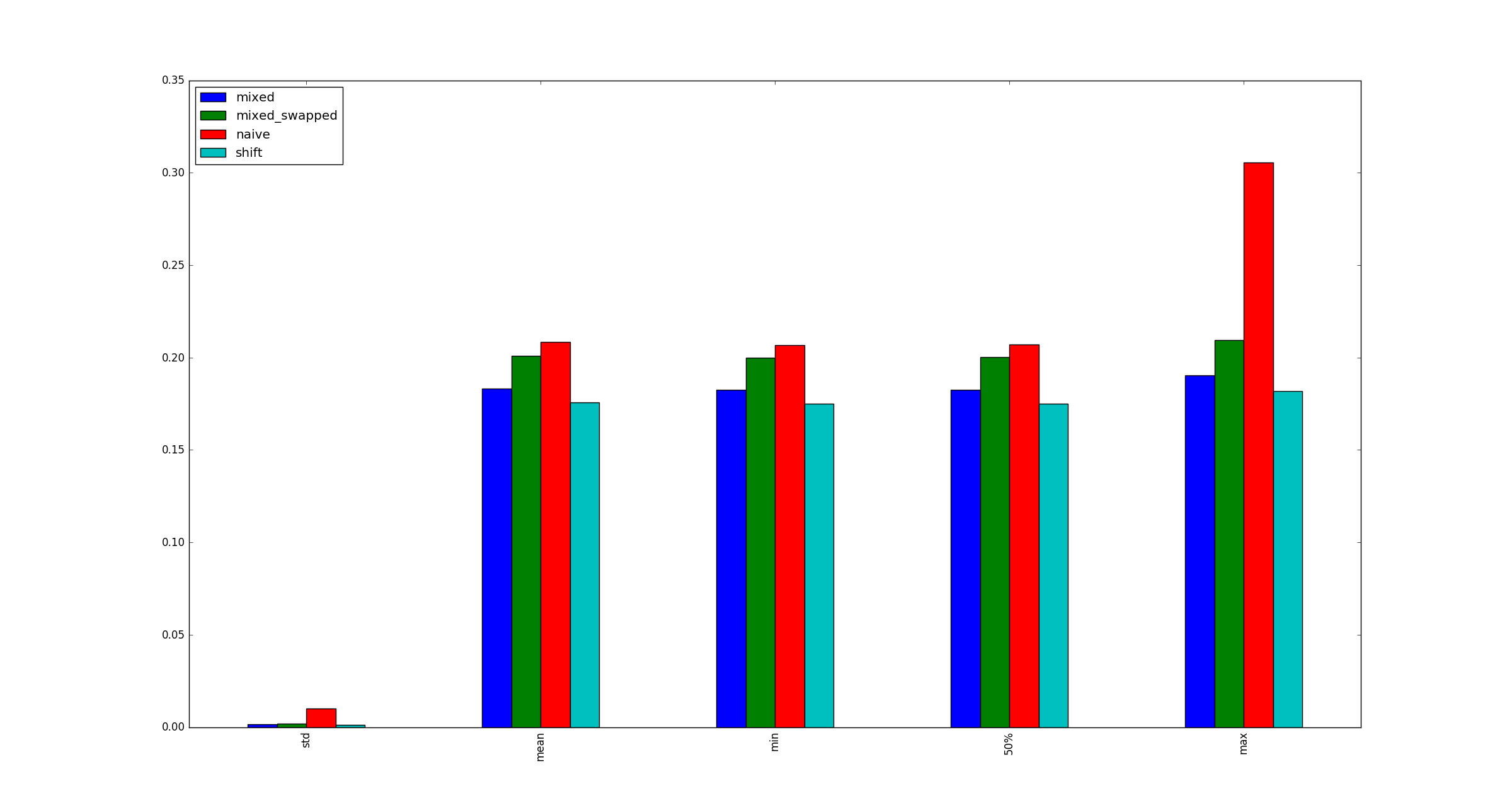
1 ответ:
это, кажется, потому, что умножение малых чисел оптимизировано в CPython 3.5, таким образом, что левые сдвиги на малые числа не являются. Положительные сдвиги влево всегда создают более крупный целочисленный объект для хранения результата, как часть вычисления, в то время как для умножения вида, используемого в тесте, специальная оптимизация избегает этого и создает целочисленный объект правильного размера. Это можно увидеть в исходный код целого числа Python реализация.
поскольку целые числа в Python имеют произвольную точность, они хранятся в виде массивов целочисленных "цифр" с ограничением на количество бит на целочисленную цифру. Поэтому в общем случае операции с целыми числами не являются одиночными операциями, а вместо этого нужно обрабатывать случай нескольких "цифр". В pyport.h этот предел определяется как 30 бит на 64-битной платформе, или 15 бит в противном случае. (Я просто назову это 30 отсюда на объяснение простое. Но обратите внимание, что если вы используете Python, скомпилированный для 32-бит, результат вашего теста будет зависеть от if
xбыли меньше, чем 32 768 или нет.)когда входы и выходы операции остаются в пределах этого 30-битного предела, операция может быть обработана оптимизированным способом вместо общего способа. Начало реализация целочисленного умножения следующим образом:
static PyObject * long_mul(PyLongObject *a, PyLongObject *b) { PyLongObject *z; CHECK_BINOP(a, b); /* fast path for single-digit multiplication */ if (Py_ABS(Py_SIZE(a)) <= 1 && Py_ABS(Py_SIZE(b)) <= 1) { stwodigits v = (stwodigits)(MEDIUM_VALUE(a)) * MEDIUM_VALUE(b); #ifdef HAVE_LONG_LONG return PyLong_FromLongLong((PY_LONG_LONG)v); #else /* if we don't have long long then we're almost certainly using 15-bit digits, so v will fit in a long. In the unlikely event that we're using 30-bit digits on a platform without long long, a large v will just cause us to fall through to the general multiplication code below. */ if (v >= LONG_MIN && v <= LONG_MAX) return PyLong_FromLong((long)v); #endif }Итак, при умножении двух целых чисел где каждый помещается в 30-битную цифру, это делается как прямое умножение интерпретатором CPython, вместо работы с целыми числами в виде массивов. (
MEDIUM_VALUE()вызываемый объект с положительным целым числом просто получает свою первую 30-разрядную цифру.) Если результат укладывается в одну 30-битную цифру,PyLong_FromLongLong()заметит это в относительно небольшом количестве операций и создаст одноразрядный целочисленный объект для его хранения.напротив, левые сдвиги не являются оптимизирован таким образом, и каждый сдвиг влево имеет дело с целым числом, сдвигаемым как массив. В частности, если вы посмотрите на исходный код
long_lshift(), в случае небольшого, но положительного сдвига влево всегда создается 2-значный целочисленный объект, если только его длина усечена до 1 позже:(мои комментарии в/*** ***/)static PyObject * long_lshift(PyObject *v, PyObject *w) { /*** ... ***/ wordshift = shiftby / PyLong_SHIFT; /*** zero for small w ***/ remshift = shiftby - wordshift * PyLong_SHIFT; /*** w for small w ***/ oldsize = Py_ABS(Py_SIZE(a)); /*** 1 for small v > 0 ***/ newsize = oldsize + wordshift; if (remshift) ++newsize; /*** here newsize becomes at least 2 for w > 0, v > 0 ***/ z = _PyLong_New(newsize); /*** ... ***/ }
целочисленное деление
вы не спрашивали о худшей производительности целочисленного деления пола по сравнению с правыми сдвигами, потому что это соответствует вашим (и моим) ожиданиям. Но деление небольшого положительного числа на другое маленькое положительное число также не так оптимизировано, как небольшие умножения. Каждый
//вычисляет коэффициент и остаток с помощью функцииlong_divrem(). Этот остаток вычисляется для небольшого делителя с умножение и хранится в недавно выделенном целочисленном объекте, который в данном ситуация тут же отбрасывается.
Comments