Инструменты для анализа производительности программы на Haskell
при решении некоторых проблем проекта Эйлера, чтобы узнать Haskell (так что в настоящее время я полностью новичок) я пришел 13. Я написал это (наивное) решение:
--Get Number of Divisors of n
numDivs :: Integer -> Integer
numDivs n = toInteger $ length [ x | x<-[2.. ((n `quot` 2)+1)], n `rem` x == 0] + 2
--Generate a List of Triangular Values
triaList :: [Integer]
triaList = [foldr (+) 0 [1..n] | n <- [1..]]
--The same recursive
triaList2 = go 0 1
where go cs n = (cs+n):go (cs+n) (n+1)
--Finds the first triangular Value with more than n Divisors
sol :: Integer -> Integer
sol n = head $ filter (x -> numDivs(x)>n) triaList2
Это решение для n=500 (sol 500) чрезвычайно медленно (работает уже более 2 часов), поэтому я задался вопросом, Как узнать, почему это решение так медленно. Есть ли какие-либо команды, которые говорят мне, где проходит большая часть времени вычислений, поэтому я знаю, какая часть моей программы haskell медленная? Что-то как простой профилировщик.
чтобы было понятно, я не прошу на более быстрое решение, но для путь найти это решение. Как бы вы начали, если бы у вас не было знаний Хаскелла?
Я пытался написать две функции, опыт испытаний, но они не нашли способ проверить, какая из них быстрее, так вот где мои проблемы начинаются.
спасибо
4 ответов:
как узнать, почему это решение так медленно. Есть ли какие-либо команды, которые говорят мне, где проходит большая часть времени вычислений, поэтому я знаю, какая часть моей программы haskell медленная?
точно! GHC предоставляет множество отличных инструментов, в том числе:
- статистика выполнения
- время профилирования
- профилирование кучи
- нить анализ
- базовый анализ.
- сравнительный бенчмаркинг
- GC tuning
учебник по использованию профилирования времени и пространства часть реального мира Хаскелл.
статистика ГХ
во-первых, убедитесь, что вы компилируете с ghc-O2. И вы можете убедиться, что это современный GHC (например, GHC 6.12.x)
в первое, что мы можем сделать, это проверить, что сбор мусора не является проблемой. Запустите программу с помощью +RTS-s
$ time ./A +RTS -s ./A +RTS -s 749700 9,961,432,992 bytes allocated in the heap 2,463,072 bytes copied during GC 29,200 bytes maximum residency (1 sample(s)) 187,336 bytes maximum slop **2 MB** total memory in use (0 MB lost due to fragmentation) Generation 0: 19002 collections, 0 parallel, 0.11s, 0.15s elapsed Generation 1: 1 collections, 0 parallel, 0.00s, 0.00s elapsed INIT time 0.00s ( 0.00s elapsed) MUT time 13.15s ( 13.32s elapsed) GC time 0.11s ( 0.15s elapsed) RP time 0.00s ( 0.00s elapsed) PROF time 0.00s ( 0.00s elapsed) EXIT time 0.00s ( 0.00s elapsed) Total time 13.26s ( 13.47s elapsed) %GC time **0.8%** (1.1% elapsed) Alloc rate 757,764,753 bytes per MUT second Productivity 99.2% of total user, 97.6% of total elapsed ./A +RTS -s 13.26s user 0.05s system 98% cpu 13.479 totalкоторый уже дает нам много информации: у вас есть только куча 2M, а GC занимает 0,8% времени. Так что не нужно беспокоиться, что распределение является проблемой.
Профили
получение профиля времени для вашей программы прямо вперед: compile with-prof-auto-all
$ ghc -O2 --make A.hs -prof -auto-all [1 of 1] Compiling Main ( A.hs, A.o ) Linking A ...и, для N=200:
$ time ./A +RTS -p 749700 ./A +RTS -p 13.23s user 0.06s system 98% cpu 13.547 totalкоторый создает файл, A. prof, содержащий:
Sun Jul 18 10:08 2010 Time and Allocation Profiling Report (Final) A +RTS -p -RTS total time = 13.18 secs (659 ticks @ 20 ms) total alloc = 4,904,116,696 bytes (excludes profiling overheads) COST CENTRE MODULE %time %alloc numDivs Main 100.0 100.0указывая, что все ваше время тратится в numDivs, и это также источник всех ваших ассигнований.
Куча Профилей
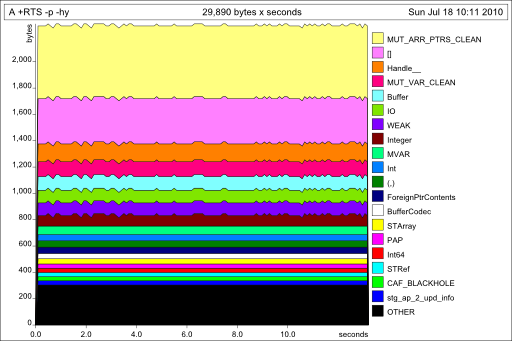
вы также можете разбить эти распределения, запустив с +RTS-p-hy, который создает A. hp, который вы можете просмотреть, конвертировав его в файл postscript (hp2ps-c A. hp), генерация:
что говорит нам, что нет ничего плохого в использовании вашей памяти: это выделение в постоянном пространстве.
Итак, ваша проблема-алгоритмическая сложность numDivs:
toInteger $ length [ x | x<-[2.. ((n `quot` 2)+1)], n `rem` x == 0] + 2исправьте это, что составляет 100% вашего времени работы, а все остальное легко.
оптимизация
это выражение является хорошим кандидатом для stream fusion оптимизация, так что Я его перепишу использовать данные.Вектор, например:
numDivs n = fromIntegral $ 2 + (U.length $ U.filter (\x -> fromIntegral n `rem` x == 0) $ (U.enumFromN 2 ((fromIntegral n `div` 2) + 1) :: U.Vector Int))который должен сливаться в один цикл без ненужных выделений кучи. То есть он будет иметь лучшую сложность (по постоянным факторам), чем версия списка. Вы можете использовать средство ghc-core (для продвинутых пользователей) для проверки промежуточного кода после оптимизации.
тестирование этого, ghc-O2 -- make Z. hs
$ time ./Z 749700 ./Z 3.73s user 0.01s system 99% cpu 3.753 totalтаким образом, он сократил время работы для N=150 на 3,5 x, без изменение самого алгоритма.
вывод
ваша проблема-numDivs. Это 100% вашего времени, и ужасные сложности. подумайте о numDivs, и как, например, для каждого N вы генерируете [2 .. n
div2 + 1] N раз. Попробуйте запомнить это, так как значения не меняются.чтобы измерить, какие из ваших функций быстрее, рассмотрите возможность использования критерий, который обеспечит статистически достоверная информация о субмикросекундных улучшениях времени выполнения.
дополнения
поскольку numDivs составляет 100% вашего времени работы, прикосновение к другим частям программы не будет иметь большого значения, однако для педагогических целей мы также можем переписать те, которые используют stream fusion.
мы также можем переписать trialList и полагаться на fusion, чтобы превратить его в цикл, который вы пишете вручную в trialList2, что такое "префикс функция "scan" (она же scanl):
triaList = U.scanl (+) 0 (U.enumFrom 1 top) where top = 10^6аналогично для sol:
sol :: Int -> Int sol n = U.head $ U.filter (\x -> numDivs x > n) triaListС таким же общим временем выполнения, но немного более чистым кодом.
ответ Dons велик, не будучи спойлером, давая прямое решение проблемы.
Здесь я хочу предложить немного инструмент что я недавно писал. Это экономит ваше время, чтобы написать SCC аннотации вручную, когда вы хотите более подробный профиль, чем по умолчаниюghc -prof -auto-all. Кроме того, что это красочно!вот пример с кодом, который вы дали (*), зеленый в порядке, красный медленно:
все время идет в создании списка делители. Это предполагает несколько вещей, которые вы можете сделать:
1. Сделайте фильтрациюn rem x == 0быстрее, но так как это встроенная функция, наверное, это уже быстро.
2. Создать более короткий список. Вы уже сделали что-то в этом направлении, проверив только доn quot 2.
3. Выбросьте генерацию списка полностью и используйте некоторую математику, чтобы получить более быстрое решение. Это обычный способ для задач Эйлера проекта.(*) я получил это, поместив ваш код в файл под названием
eu13.hsдобавление главный функцияmain = print $ sol 90. Тогда бегитеvisual-prof -px eu13.hs eu13и в результатеeu13.hs.html.

Haskell связанные Примечание:
triaList2конечно быстрее, чемtriaList, потому что последний выполняет много ненужных вычислений. Это понадобится квадратичное время, чтобы вычислить n первых элементовtriaList, но линейные поtriaList2. Существует еще один элегантный (и эффективный) способ определения бесконечного ленивого списка Треугольных чисел:triaList = 1 : zipWith (+) triaList [2..]Math related Примечание: нет необходимости проверять все делители до n / 2, достаточно проверить до sqrt(n).
вы можете запустить программу с флагами, чтобы включить профилирование времени. Что-то вроде этого:
./program +RTS -P -sprogram.stats -RTSЭто должно запустить программу и создать файл с именем program.статистика, которая будет иметь, сколько времени было потрачено в каждой функции. Вы можете найти дополнительную информацию о профилировании с помощью GHC в GHC руководство пользователя. Для бенчмаркинга существует библиотека критериев. Я нашел этой сообщение в блоге имеет полезное введение.
Comments