12 ответов:
Если вы ищете реализацию ANSI C, вы можете "украсть" ее из FreeBSD. Файл, который вы ищете, называется radix.c. Он используется для управления данными маршрутизации в ядре.
Я понимаю, что вопрос был о готовых реализаций, но для справки...
прежде чем перейти на Джуди вы должны были прочитать "сравнение производительности Джуди с хэш-таблицами". Тогда Google название, скорее всего, даст вам всю жизнь обсуждения и опровержения читать.
один явно кэш-сознательный trie, о котором я знаю, - это HAT-trie.
шляпа-три, при правильной реализации, очень круто. Однако, для поиск префикса вам нужен шаг сортировки на хэш-ведрах, который несколько противоречит идее структуры префикса.
несколько проще trie является burst-trie что по существу дает вам интерполяцию между стандартным деревом какого-то вида (например, BST) и trie. Мне это нравится концептуально, и это гораздо проще реализовать.
Мне повезло с libTrie. Он не может быть специально оптимизирован для кэша, но производительность всегда была приличной для моих приложений.
GCC поставляется с несколькими структурами данных в рамках своих "структур данных на основе политики". Это включает в себя несколько реализаций trie.
http://gcc.gnu.org/onlinedocs/libstdc++/ext/pb_ds/trie_based_containers.html
ссылки
- A реализация двойного массива Trie статьи (включает в себя
Cреализации)- корзина - динамическая структура данных LC-trie и хэша -- (ссылка на PDF 2006 года, описывающая динамический LC-trie, используемый в ядре Linux для реализации поиска адресов в таблице маршрутизации IP
Джуди массивы: очень быстрые и эффективные в памяти упорядоченные разреженные динамические массивы для битов, целых чисел и строк. Массивы Judy быстрее и эффективнее памяти, чем любое двоичное дерево поиска (ВКЛ. Авл & красно-черные деревья).
вы также можете попробовать TommyDS в http://tommyds.sourceforge.net/
смотрите страницу бенчмарки на сайте для сравнения скорости с недтри и Джуди.
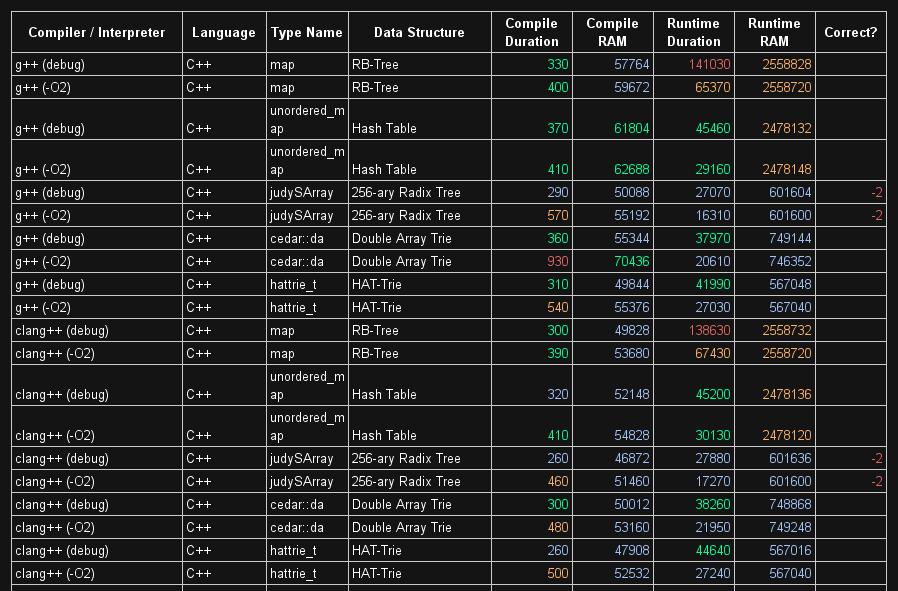
оптимизация кэша-это то, что вам, вероятно, придется сделать, потому что вам нужно будет поместить данные в одну cacheline, которая обычно составляет что-то вроде 64 байт (что, вероятно, будет работать, если вы начнете объединять данные, такие как указатели). Но это сложно :-)
взрыв в боре кажется, немного больше места эффективным. Я не уверен, сколько эффективности кэша вы можете получить из любого индекса, так как кэши процессора настолько малы. Однако этот вид trie достаточно компактен, чтобы хранить большие наборы данных в ОЗУ (где обычный Trie не будет).
Я написал реализацию Scala burst trie, которая также включает в себя некоторые методы экономии пространства, которые я нашел в типе GWT-ahead реализация.
У меня были очень хорошие результаты (очень хороший баланс между производительностью и размером) с marisa-trie по сравнению с несколькими реализациями TRIE, упомянутыми в моем наборе данных.
совместное использование моей" быстрой " реализации для Trie, протестированной только в базовом сценарии:
#define ENG_LET 26 class Trie { class TrieNode { public: TrieNode* sons[ENG_LET]; int strsInBranch; bool isEndOfStr; void print() { cout << "----------------" << endl; cout << "sons.."; for(int i=0; i<ENG_LET; ++i) { if(sons[i] != NULL) cout << " " << (char)('a'+i); } cout << endl; cout << "strsInBranch = " << strsInBranch << endl; cout << "isEndOfStr = " << isEndOfStr << endl; for(int i=0; i<ENG_LET; ++i) { if(sons[i] != NULL) sons[i]->print(); } } TrieNode(bool _isEndOfStr = false):isEndOfStr(_isEndOfStr), strsInBranch(0) { for(int i=0; i<ENG_LET; ++i) { sons[i] = NULL; } } ~TrieNode() { for(int i=0; i<ENG_LET; ++i) { delete sons[i]; sons[i] = NULL; } } }; TrieNode* head; public: Trie() { head = new TrieNode();} ~Trie() { delete head; } void print() { cout << "Preorder Print : " << endl; head->print(); } bool isExists(const string s) { TrieNode* curr = head; for(int i=0; i<s.size(); ++i) { int letIdx = s[i]-'a'; if(curr->sons[letIdx] == NULL) { return false; } curr = curr->sons[letIdx]; } return curr->isEndOfStr; } void addString(const string& s) { if(isExists(s)) return; TrieNode* curr = head; for(int i=0; i<s.size(); ++i) { int letIdx = s[i]-'a'; if(curr->sons[letIdx] == NULL) { curr->sons[letIdx] = new TrieNode(); } ++curr->strsInBranch; curr = curr->sons[letIdx]; } ++curr->strsInBranch; curr->isEndOfStr = true; } void removeString(const string& s) { if(!isExists(s)) return; TrieNode* curr = head; for(int i=0; i<s.size(); ++i) { int letIdx = s[i]-'a'; if(curr->sons[letIdx] == NULL) { assert(false); return; //string not exists, will not reach here } if(curr->strsInBranch==1) { //just 1 str that we want remove, remove the whole branch delete curr; return; } //more than 1 son --curr->strsInBranch; curr = curr->sons[letIdx]; } curr->isEndOfStr = false; } void clear() { for(int i=0; i<ENG_LET; ++i) { delete head->sons[i]; head->sons[i] = NULL; } } };
Comments