Понимание Keras LSTMs
Я пытаюсь примирить мое понимание LSTMs и указал здесь в этот пост Кристофер Ола выполнены в водоснабжении. Я следую за блог написанный Джейсоном Браунли для учебника Keras. То, что меня в основном смущает,
- изменение формы ряда данных в
[samples, time steps, features]и - статусные LSTMs
давайте сосредоточимся на двух вышеупомянутых вопросах со ссылкой на код вставлено ниже:
# reshape into X=t and Y=t+1
look_back = 3
trainX, trainY = create_dataset(train, look_back)
testX, testY = create_dataset(test, look_back)
# reshape input to be [samples, time steps, features]
trainX = numpy.reshape(trainX, (trainX.shape[0], look_back, 1))
testX = numpy.reshape(testX, (testX.shape[0], look_back, 1))
########################
# The IMPORTANT BIT
##########################
# create and fit the LSTM network
batch_size = 1
model = Sequential()
model.add(LSTM(4, batch_input_shape=(batch_size, look_back, 1), stateful=True))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
for i in range(100):
model.fit(trainX, trainY, nb_epoch=1, batch_size=batch_size, verbose=2, shuffle=False)
model.reset_states()
Примечание: create_dataset принимает последовательность длины N и возвращает a N-look_back массив из которого каждый элемент является look_back последовательность длины.
что такое временные шаги и функции?
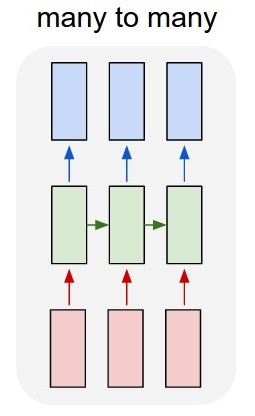
как видно, TrainX представляет собой трехмерный массив с Time_steps и функцией, являющейся последними двумя измерениями соответственно (3 и 1 в этом конкретном коде). Что касается изображения ниже, означает ли это, что мы рассматриваем many to one case, где число из розовых коробок есть 3? Или это буквально означает, что длина цепи равна 3 (т. е. рассматриваются только 3 зеленых ящика). 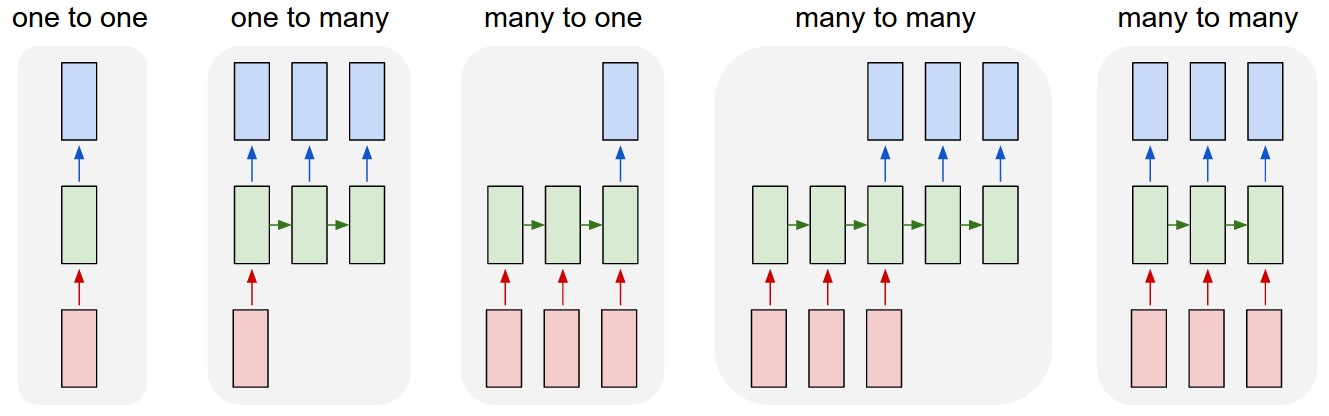
имеет ли значение аргумент features, когда мы рассматриваем многомерные ряды? например, моделирование двух финансовых запасов одновременно?
Stateful LSTMs
означает ли stateful LSTMs, что мы сохраняем значения памяти ячейки между запусками пакетов? Если это так, batch_size один, и память сбрасывается между тренировочными прогонами так какой смысл говорить, что он был статусным. Я предполагаю, что это связано с тем, что данные обучения не перемешиваются, но я не уверен, как это сделать.
какие мысли?
Ссылка на изображение: http://karpathy.github.io/2015/05/21/rnn-effectiveness/
Edit 1:
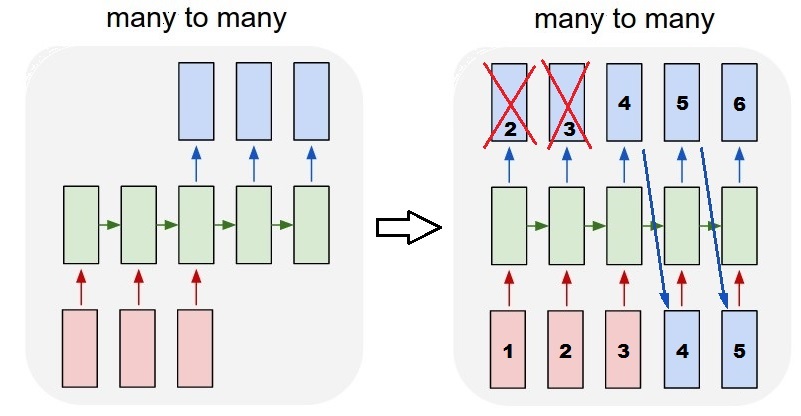
немного смущен комментарием @van о том, что красные и зеленые коробки равны. Итак, просто чтобы подтвердить, соответствуют ли следующие вызовы API развернутым диаграммам? Особенно отмечая вторую диаграмму (batch_size был произвольно выбран.):
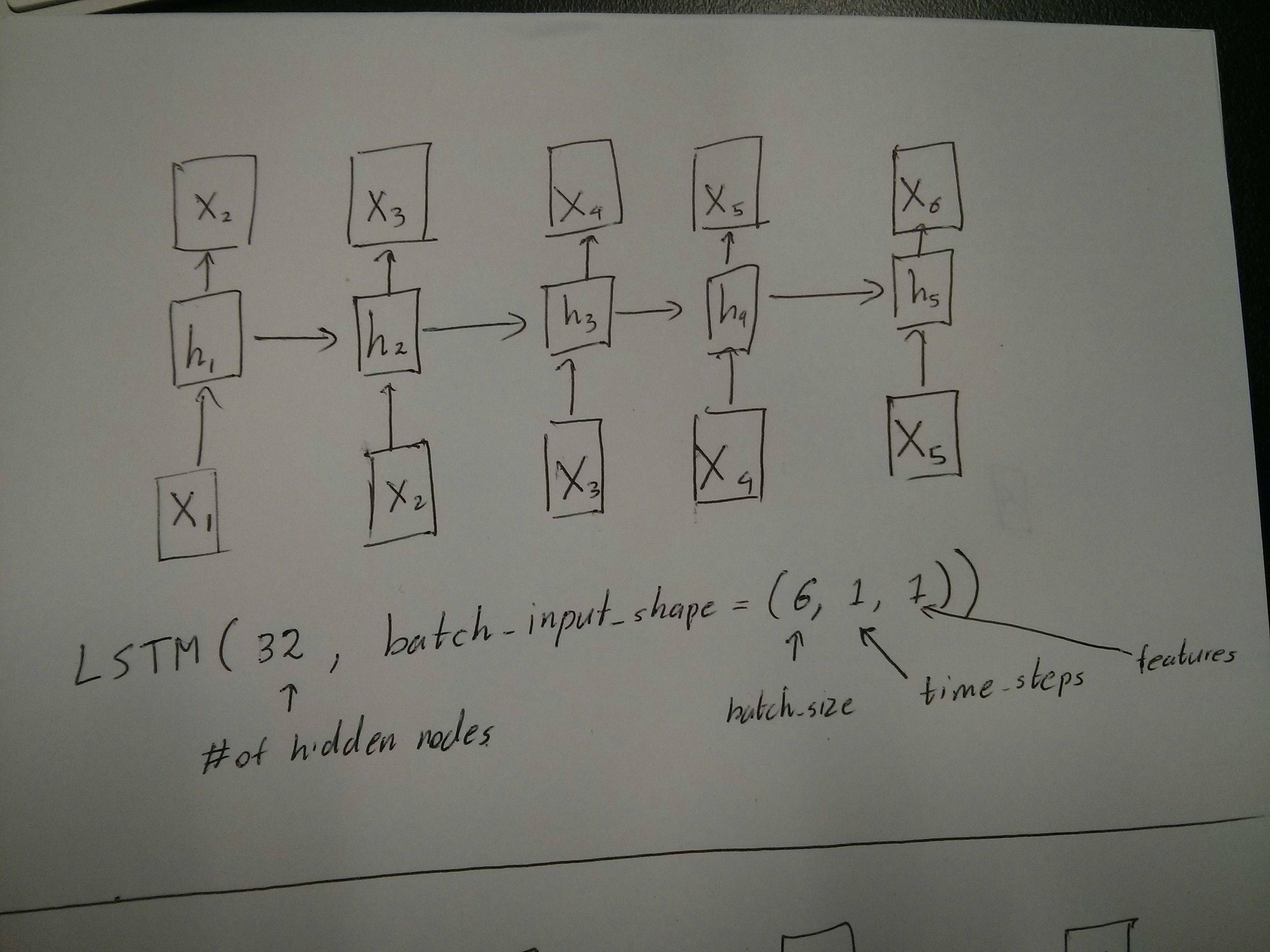
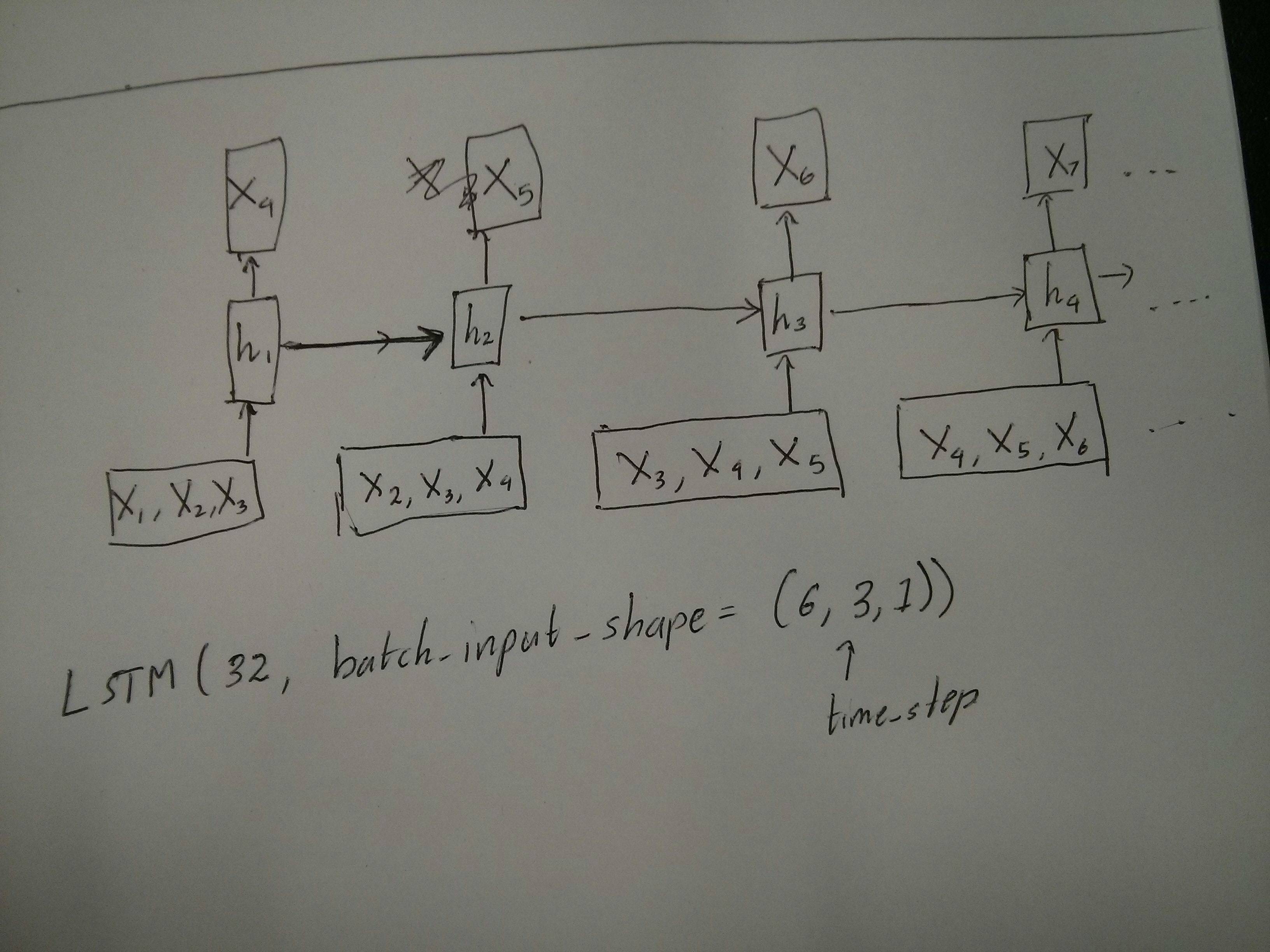
Edit 2:
для людей, которые прошли курс глубокого обучения Udacity и все еще путают аргумент time_step, посмотрите на следующее обсуждение:https://discussions.udacity.com/t/rnn-lstm-use-implementation/163169
обновление:
получается model.add(TimeDistributed(Dense(vocab_len))) было то, что я ищу. Вот такой пример: https://github.com/sachinruk/ShakespeareBot
Update2:
я суммировал большую часть моего понимания LSTMs здесь:https://www.youtube.com/watch?v=ywinX5wgdEU
3 ответов:
прежде всего, вы выбираете отличные учебники(1,2), чтобы начать.
что означает Time-step:
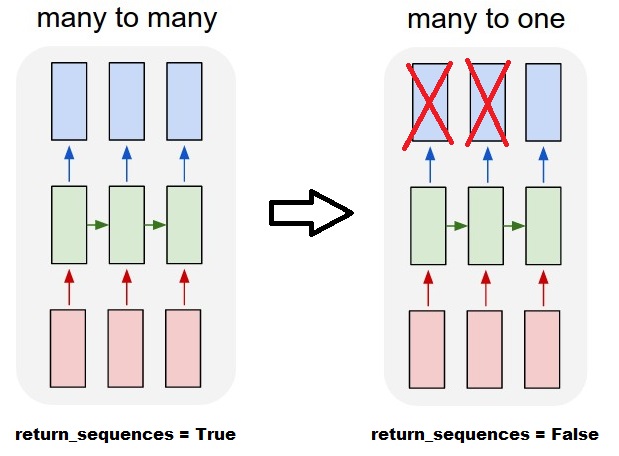
Time-steps==3В X. форма (описывающая форму данных) означает, что есть три розовые коробки. Поскольку в Keras каждый шаг требует ввода, поэтому количество зеленых ящиков обычно должно равняться количеству красных ящиков. Если только вы не взломаете структуру.многие ко многим и многие к одному: в керасе есть
return_sequencesпараметр при инициализацииLSTMилиGRUилиSimpleRNN. Когдаreturn_sequencesиFalse(по умолчанию), то многие к одному как показано на рисунке. Его возвращенная форма(batch_size, hidden_unit_length), которые представляют собой последнее состояние. Когдаreturn_sequencesиTrue, то это многие ко многим. Его возвращенная форма(batch_size, time_step, hidden_unit_length)имеет ли значение аргумент features: аргумент функции означает "как велика ваша красная коробка" или каков входной размер каждого шага. Если вы хотите прогнозировать, скажем, из 8 видов рыночной информации, то вы можете генерировать свои данные с помощью
feature==8.Stateful вы можете найти исходный код. При инициализации состояния, если
stateful==True, то состояние из последнего обучения будет использоваться в качестве начального состояния, в противном случае он будет генерировать новое состояние. Я еще не включилstatefulеще. Однако, я не согласен с тем, чтоbatch_sizeможет быть только 1, когдаstateful==True.в настоящее время, вы генерируете свои данные с собранными данными. Изображение информация о запасах поступает в виде потока, а не ждать в течение дня, чтобы собрать все последовательные, вы хотели бы генерировать входные данные онлайн во время обучения/прогнозирования с помощью сети. Если у вас есть 400 акций, разделяющих одну и ту же сеть, то вы можете установить
batch_size==400.
в дополнение к принятому ответу, этот ответ показывает поведение keras и как достичь каждой картины.
поведение генерала Кераса
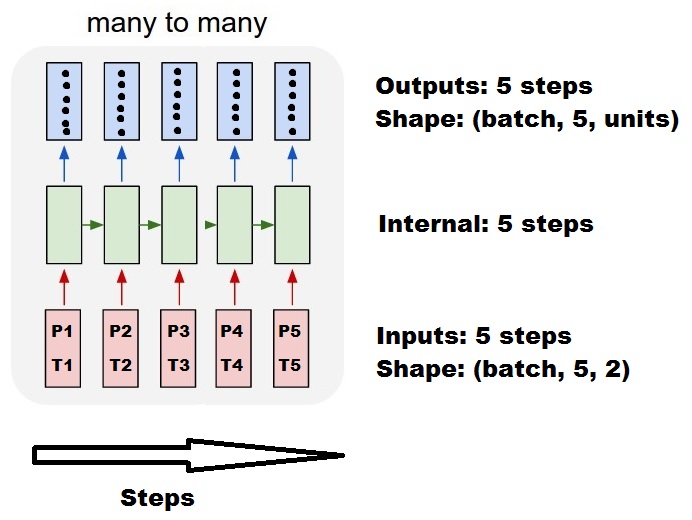
стандартная внутренняя обработка keras всегда много ко многим, как на следующем рисунке (где я использовал
features=2, давление и температура, как раз как пример):
на этом изображении я увеличил количество шагов до 5, чтобы избежать путаницы с другими размеры.
для этого примера:
- у нас есть N масляных баков
- мы потратили 5 часов, принимая меры ежечасно (временные шаги)
- мы измерили две особенности:
- Давление P
- Температура T
наш входной массив должен быть чем-то похожим на
(N,5,2):[ Step1 Step2 Step3 Step4 Step5 Tank A: [[Pa1,Ta1], [Pa2,Ta2], [Pa3,Ta3], [Pa4,Ta4], [Pa5,Ta5]], Tank B: [[Pb1,Tb1], [Pb2,Tb2], [Pb3,Tb3], [Pb4,Tb4], [Pb5,Tb5]], .... Tank N: [[Pn1,Tn1], [Pn2,Tn2], [Pn3,Tn3], [Pn4,Tn4], [Pn5,Tn5]], ]входы для раздвижных окон
чаще, слои ЛСТМ являются предполагается обработать все последовательности. Разделение окон может быть не лучшей идеей. Слой имеет внутренние состояния о том, как последовательность развивается по мере продвижения вперед. Окна исключают возможность изучения длинных последовательностей, ограничивая все последовательности размером окна.
в windows каждое окно является частью длинной исходной последовательности, но Keras они будут рассматриваться каждый как независимая последовательность:
[ Step1 Step2 Step3 Step4 Step5 Window A: [[P1,T1], [P2,T2], [P3,T3], [P4,T4], [P5,T5]], Window B: [[P2,T2], [P3,T3], [P4,T4], [P5,T5], [P6,T6]], Window C: [[P3,T3], [P4,T4], [P5,T5], [P6,T6], [P7,T7]], .... ]обратите внимание, что в этом случае у вас есть только изначально одна последовательность, но вы делите ее на множество последовательностей для создания окон.
понятие "что такое последовательность" является абстрактным. Важными частями являются:
- вы можете иметь партии со многими отдельными последовательностями
- что делает последовательности последовательностями, так это то, что они развиваются поэтапно (обычно временные шаги)
достижение каждого случая с "одиночными слоями"
достигать стандарта много к многие:
вы можете достичь многих ко многим с помощью простого слоя LSTM, используя
return_sequences=True:outputs = LSTM(units, return_sequences=True)(inputs) #output_shape -> (batch_size, steps, units)достижение многих к одному:
используя тот же самый слой, keras будет делать ту же самую внутреннюю предварительную обработку, но когда вы используете
return_sequences=False(или просто проигнорируйте этот аргумент), keras автоматически отбросит шаги, предшествующие последнее:
outputs = LSTM(units)(inputs) #output_shape -> (batch_size, units) --> steps were discarded, only the last was returnedдостижение один-ко-многим
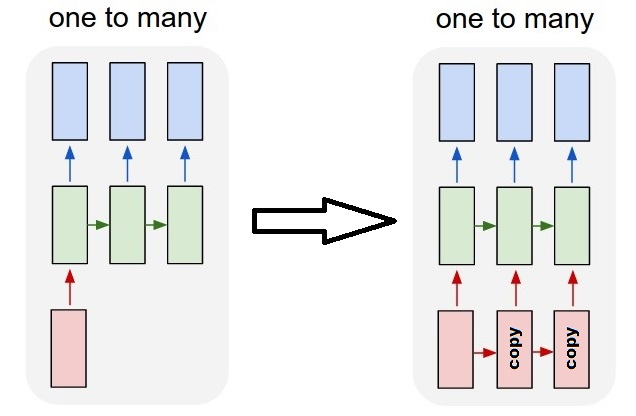
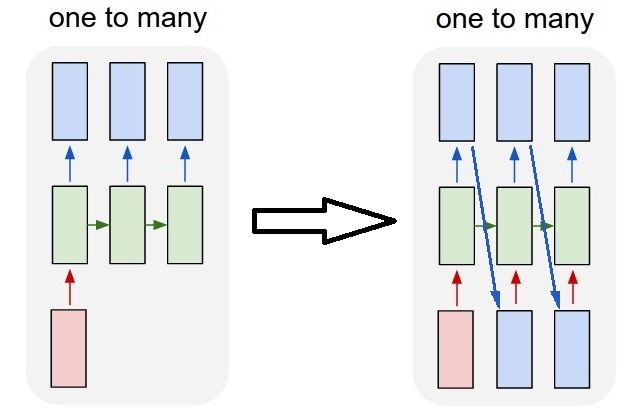
теперь это не поддерживается только слоями keras LSTM. Вам придется создать свою собственную стратегию, чтобы умножить шаги. Есть два хороших подхода:
- создайте постоянный многоступенчатый ввод, повторяя тензор
- использовать
stateful=Trueчтобы рекуррентно взять выход одного шага и служить ему в качестве входа следующего шага (потребностиoutput_features == input_features)один ко многим с повторением вектора
чтобы соответствовать стандартному поведению keras, нам нужны входные данные в шагах, поэтому мы просто повторяем входные данные для длины, которую мы хотим:
outputs = RepeatVector(steps)(inputs) #where inputs is (batch,features) outputs = LSTM(units,return_sequences=True)(outputs) #output_shape -> (batch_size, steps, units)понимание состояния = True
один из возможных способов использованияstateful=True(кроме того, избегая загрузки данных, которые не могут соответствовать памяти вашего компьютера на один раз)Stateful позволяет нам вводить" части " последовательностей поэтапно. Разница в следующем:
- In
stateful=False, вторая партия содержит целые новые последовательности, независимые от первой партии- In
stateful=True, вторая партия продолжает первую партию, расширяя те же последовательности.это похоже на разделение последовательностей в windows тоже, с этими двумя основными различиями:
- эти окна делать не накладывай!!
stateful=Trueэти окна будут соединены в одну длинную последовательностьна
stateful=True, каждый новый пакет будет интерпретироваться как продолжение предыдущего пакета (пока вы не вызоветеmodel.reset_states()).
- последовательность 1 в партии 2 будет продолжать последовательность 1 в партии 1.
- последовательность 2 в партии 2 будет продолжать последовательность 2 в партии 1.
- последовательность n в партии 2 будет продолжать последовательность n в партии 1.
пример входных данных, пакет 1 содержит шаги 1 и 2, Пакет 2 содержит шаги от 3 до 5:
BATCH 1 BATCH 2 [ Step1 Step2 | [ Step3 Step4 Step5 Tank A: [[Pa1,Ta1], [Pa2,Ta2], | [Pa3,Ta3], [Pa4,Ta4], [Pa5,Ta5]], Tank B: [[Pb1,Tb1], [Pb2,Tb2], | [Pb3,Tb3], [Pb4,Tb4], [Pb5,Tb5]], .... | Tank N: [[Pn1,Tn1], [Pn2,Tn2], | [Pn3,Tn3], [Pn4,Tn4], [Pn5,Tn5]], ] ]обратите внимание на выравнивание танков в партии 1 и партии 2! Вот почему нам нужно
shuffle=False(если мы используем только одну последовательность, конечно).вы можете иметь любое количество партий, бесконечно. (Для того, чтобы иметь переменную длину в каждой партии, используйте
input_shape=(None,features).один ко многим с stateful=True
для нашего случая здесь, мы будем использовать только 1 шаг на партию, потому что мы хотим получить один шаг вывода и сделать его входным.
обратите внимание, что поведение на картинке не "вызвано"
stateful=True. Мы заставим это поведение в ручном цикле ниже. В этом примереstateful=Trueэто то, что" позволяет " нам остановить последовательность, манипулировать тем, что мы хотим, и продолжать с того места, где мы остановились.
честно говоря, повторный подход, вероятно, лучше выбор для этого случая. Но так как мы изучаем
stateful=True, это хороший пример. Лучший способ использовать это-следующий случай "многие ко многим".слоев:
outputs = LSTM(units=features, stateful=True, return_sequences=True, #just to keep a nice output shape even with length 1 input_shape=(None,features))(inputs) #units = features because we want to use the outputs as inputs #None because we want variable length #output_shape -> (batch_size, steps, units)теперь нам понадобится ручной цикл для предсказаний:
input_data = someDataWithShape((batch, 1, features)) #important, we're starting new sequences, not continuing old ones: model.reset_states() output_sequence = [] last_step = input_data for i in steps_to_predict: new_step = model.predict(last_step) output_sequence.append(new_step) last_step = new_step #end of the sequences model.reset_states()многие ко многим с stateful=True
теперь, здесь, мы получаем очень хорошее приложение: учитывая входную последовательность, попробуйте предсказать ее будущие неизвестные шаги.
мы используем тот же метод, что и в "один ко многим" выше, с той разницей, что:
- мы будем использовать саму последовательность, чтобы быть целевыми данными, на один шаг вперед
- мы знаем часть последовательности (поэтому мы отбрасываем эту часть результатов).
слой (такой же, как выше):
outputs = LSTM(units=features, stateful=True, return_sequences=True, input_shape=(None,features))(inputs) #units = features because we want to use the outputs as inputs #None because we want variable length #output_shape -> (batch_size, steps, units)обучение:
мы будем готовить нашу модель, чтобы предсказать следующий шаг последовательности:
totalSequences = someSequencesShaped((batch, steps, features)) #batch size is usually 1 in these cases (often you have only one Tank in the example) X = totalSequences[:,:-1] #the entire known sequence, except the last step Y = totalSequences[:,1:] #one step ahead of X #loop for resetting states at the start/end of the sequences: for epoch in range(epochs): model.reset_states() model.train_on_batch(X,Y)предсказания:
первый этап нашего прогнозирования включает в себя "корректировку состояний". Вот почему мы собираемся предсказать всю последовательность снова, даже если мы уже знаем эту ее часть:
model.reset_states() #starting a new sequence predicted = model.predict(totalSequences) firstNewStep = predicted[:,-1:] #the last step of the predictions is the first future stepтеперь мы переходим к циклу, как в случае один ко многим. Но не сбрасывайте здесь состояния!. Мы хотим, чтобы модель знала, на каком шаге последовательности она находится (и она знает, что это на первом новом шаге из-за предсказания, которое мы только что сделали выше)
output_sequence = [firstNewStep] last_step = firstNewStep for i in steps_to_predict: new_step = model.predict(last_step) output_sequence.append(new_step) last_step = new_step #end of the sequences model.reset_states()этот подход был использован в этих ответах и файле:
- прогнозирование многократного временного шага вперед временного ряда с использованием LSTM
- как использовать модель Keras для прогнозирования будущих дат или событий?
- https://github.com/danmoller/TestRepo/blob/master/TestBookLSTM.ipynb
достижение сложные конфигурации
во всех приведенных выше примерах, я показал поведение "один слой".
вы можете, конечно, укладывать много слоев друг на друга, не обязательно все по одному шаблону, и создавать свои собственные модели.
один интересный пример, который появляется является "автоэнкодер", который имеет "многие к одному кодеру", а затем "один ко многим" декодер:
кодировщик:
inputs = Input((steps,features)) #a few many to many layers: outputs = LSTM(hidden1,return_sequences=True)(inputs) outputs = LSTM(hidden2,return_sequences=True)(outputs) #many to one layer: outputs = LSTM(hidden3)(outputs) encoder = Model(inputs,outputs)декодер:
С помощью метода "repeat";
inputs = Input((hidden3,)) #repeat to make one to many: outputs = RepeatVector(steps)(inputs) #a few many to many layers: outputs = LSTM(hidden4,return_sequences=True)(outputs) #last layer outputs = LSTM(features,return_sequences=True)(outputs) decoder = Model(inputs,outputs)Autoencoder:
inputs = Input((steps,features)) outputs = encoder(inputs) outputs = decoder(outputs) autoencoder = Model(inputs,outputs)поезд
fit(X,X)
когда у вас есть return_sequences в вашем последнем слое RNN, вы не можете использовать простой плотный слой вместо использования TimeDistributed.
вот пример кода, который может помочь другим.
слова = keras.слои.Input(batch_shape=(None, self.maxSequenceLength), name = "input")
# Build a matrix of size vocabularySize x EmbeddingDimension # where each row corresponds to a "word embedding" vector. # This layer will convert replace each word-id with a word-vector of size Embedding Dimension. embeddings = keras.layers.embeddings.Embedding(self.vocabularySize, self.EmbeddingDimension, name = "embeddings")(words) # Pass the word-vectors to the LSTM layer. # We are setting the hidden-state size to 512. # The output will be batchSize x maxSequenceLength x hiddenStateSize hiddenStates = keras.layers.GRU(512, return_sequences = True, input_shape=(self.maxSequenceLength, self.EmbeddingDimension), name = "rnn")(embeddings) hiddenStates2 = keras.layers.GRU(128, return_sequences = True, input_shape=(self.maxSequenceLength, self.EmbeddingDimension), name = "rnn2")(hiddenStates) denseOutput = TimeDistributed(keras.layers.Dense(self.vocabularySize), name = "linear")(hiddenStates2) predictions = TimeDistributed(keras.layers.Activation("softmax"), name = "softmax")(denseOutput) # Build the computational graph by specifying the input, and output of the network. model = keras.models.Model(input = words, output = predictions) # model.compile(loss='kullback_leibler_divergence', \ model.compile(loss='sparse_categorical_crossentropy', \ optimizer = keras.optimizers.Adam(lr=0.009, \ beta_1=0.9,\ beta_2=0.999, \ epsilon=None, \ decay=0.01, \ amsgrad=False))
Comments