Что же ТФ.НН.conv2d сделать в тензорном потоке?
Я смотрел на документы tensorflow о tf.nn.conv2dздесь. Но я не могу понять, что он делает или чего он пытается достичь. Он говорит на документах,
#1: сглаживает фильтр до 2-D матрицы с формой
[filter_height * filter_width * in_channels, output_channels].
что это? Это поэлементное умножение или просто матричное умножение? Я также не мог понять два других пункта, упомянутых в документах. У меня есть написал их ниже :
# 2: извлекает патчи изображения из входного тензора, чтобы сформировать виртуальный тензор формы
[batch, out_height, out_width, filter_height * filter_width * in_channels].
# 3: для каждого патча, справа-умножает матрицу фильтра и вектор патча изображения.
было бы очень полезно, если кто-нибудь может привести пример, кусок кода (очень полезно) может и объяснить, что происходит и почему операция такая.
Я попробовал кодировать небольшую часть и распечатать форму операции. И все же я не могу понять.
Я пробовал что-то вроде этого:
op = tf.shape(tf.nn.conv2d(tf.random_normal([1,10,10,10]),
tf.random_normal([2,10,10,10]),
strides=[1, 2, 2, 1], padding='SAME'))
with tf.Session() as sess:
result = sess.run(op)
print(result)
Я понимаю, что биты и куски сверточных нейронных сетей. Я изучал их здесь. Но реализация на tensorflow-это не то, что я ожидал. Поэтому и возник вопрос.
EDIT:
Итак, я реализовал гораздо более простой код. Но я не могу понять, что происходит. Я имею в виду, как результаты таковы. Было бы очень полезно, если бы кто-нибудь мог сказать мне, какой процесс дает этот результат.
input = tf.Variable(tf.random_normal([1,2,2,1]))
filter = tf.Variable(tf.random_normal([1,1,1,1]))
op = tf.nn.conv2d(input, filter, strides=[1, 1, 1, 1], padding='SAME')
init = tf.initialize_all_variables()
with tf.Session() as sess:
sess.run(init)
print("input")
print(input.eval())
print("filter")
print(filter.eval())
print("result")
result = sess.run(op)
print(result)
выход
input
[[[[ 1.60314465]
[-0.55022103]]
[[ 0.00595062]
[-0.69889867]]]]
filter
[[[[-0.59594476]]]]
result
[[[[-0.95538563]
[ 0.32790133]]
[[-0.00354624]
[ 0.41650501]]]]
5 ответов:
2D свертка вычисляется аналогичным образом можно было бы вычислить 1D свертка: вы перемещаете свое ядро по входу, вычисляете поэлементные умножения и суммируете их. Но вместо того, чтобы ваше ядро / вход были массивом, здесь они являются матрицами.
в самом базовом примере нет заполнения и шага=1. Давайте предположим, что ваш
inputиkernelнесколько:когда вы свое ядро вы получите следующий вывод:
, которая рассчитывается следующим образом:
- 14 = 4 * 1 + 3 * 0 + 1 * 1 + 2 * 2 + 1 * 1 + 0 * 0 + 1 * 0 + 2 * 0 + 4 * 1
- 6 = 3 * 1 + 1 * 0 + 0 * 1 + 1 * 2 + 0 * 1 + 1 * 0 + 2 * 0 + 4 * 0 + 1 * 1
- 6 = 2 * 1 + 1 * 0 + 0 * 1 + 1 * 2 + 2 * 1 + 4 * 0 + 3 * 0 + 1 * 0 + 0 * 1
- 12 = 1 * 1 + 0 * 0 + 1 * 1 + 2 * 2 + 4 * 1 + 1 * 0 + 1 * 0 + 0 * 0 + 2 * 1
ТФ это conv2d функция вычисляет свертки в пакетах и использует немного другой формат. Для входа это
[batch, in_height, in_width, in_channels]для ядра это[filter_height, filter_width, in_channels, out_channels]. Поэтому нам нужно предоставить данные в правильном формате:import tensorflow as tf k = tf.constant([ [1, 0, 1], [2, 1, 0], [0, 0, 1] ], dtype=tf.float32, name='k') i = tf.constant([ [4, 3, 1, 0], [2, 1, 0, 1], [1, 2, 4, 1], [3, 1, 0, 2] ], dtype=tf.float32, name='i') kernel = tf.reshape(k, [3, 3, 1, 1], name='kernel') image = tf.reshape(i, [1, 4, 4, 1], name='image')после этого свертка вычисляется с помощью:
res = tf.squeeze(tf.nn.conv2d(image, kernel, [1, 1, 1, 1], "VALID")) # VALID means no padding with tf.Session() as sess: print sess.run(res)и будет эквивалентно тому, который мы рассчитали вручную.
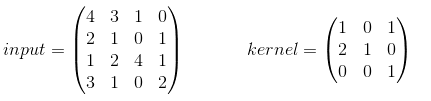
хорошо, я думаю, что это самый простой способ объяснить все это.
ваш пример-1 Изображение, размер 2x2, с 1 каналом. У вас есть 1 фильтр с размером 1x1 и 1 канал (размер-Высота x Ширина X каналы x количество фильтров).
в этом простом случае результирующее изображение канала 2x2, 1 (размер 1x2x2x1, количество изображений X Высота x Ширина X каналы) является результатом умножения значения фильтра на каждый пиксель изображение.
теперь давайте попробуем больше каналов:
input = tf.Variable(tf.random_normal([1,3,3,5])) filter = tf.Variable(tf.random_normal([1,1,5,1])) op = tf.nn.conv2d(input, filter, strides=[1, 1, 1, 1], padding='VALID')здесь изображение 3x3 и фильтр 1x1 имеют по 5 каналов. Полученное изображение будет 3x3 с 1 каналом (размер 1x3x3x1), где значение каждого пикселя является точечным произведением по каналам фильтра с соответствующим пикселем во входном изображении.
теперь с фильтром 3x3
input = tf.Variable(tf.random_normal([1,3,3,5])) filter = tf.Variable(tf.random_normal([3,3,5,1])) op = tf.nn.conv2d(input, filter, strides=[1, 1, 1, 1], padding='VALID')здесь мы получаем изображение 1x1, с 1 каналом (размер 1x1x1x1). Значение сумма 9, 5-элементных точечных произведений. Но вы можете просто назвать это 45-элементным точечным продуктом.
теперь с большим изображения
input = tf.Variable(tf.random_normal([1,5,5,5])) filter = tf.Variable(tf.random_normal([3,3,5,1])) op = tf.nn.conv2d(input, filter, strides=[1, 1, 1, 1], padding='VALID')выход 3x3 1-канальное изображение (размер 1x3x3x1). Каждое из этих значений представляет собой сумму 9,5-элементных точечных произведений.
каждый выход производится путем центрирования фильтра на одном из 9 центральных пикселей входного изображения, так что ни один из фильтров не торчит. Элемент
xs ниже представляют центры фильтров для каждого выходной пиксель...... .xxx. .xxx. .xxx. .....
теперь с" тем же " дополнением:
input = tf.Variable(tf.random_normal([1,5,5,5])) filter = tf.Variable(tf.random_normal([3,3,5,1])) op = tf.nn.conv2d(input, filter, strides=[1, 1, 1, 1], padding='SAME')это дает выходное изображение 5x5 (размер 1x5x5x1). Это делается путем центрирования фильтра в каждой позиции на изображении.
любой из 5-элементных точечных продуктов, где фильтр торчит за краем изображения, получает значение нуля.
таким образом, углы-это только суммы 4, 5-элементных точечных продуктов.
теперь с несколько фильтры.
input = tf.Variable(tf.random_normal([1,5,5,5])) filter = tf.Variable(tf.random_normal([3,3,5,7])) op = tf.nn.conv2d(input, filter, strides=[1, 1, 1, 1], padding='SAME')это все еще дает выходное изображение 5x5, но с 7 каналами (размер 1x5x5x7). Где каждый канал производится одним из фильтров в наборе.
теперь с шагом 2,2:
input = tf.Variable(tf.random_normal([1,5,5,5])) filter = tf.Variable(tf.random_normal([3,3,5,7])) op = tf.nn.conv2d(input, filter, strides=[1, 2, 2, 1], padding='SAME')теперь результат все еще имеет 7 каналов, но только 3x3 (размер 1x3x3x7).
это связано с тем, что вместо центрирования фильтров в каждой точке изображения фильтры центрируются в каждой другой точке изображения, предпринимая шаги (шаги) шириной 2. Элемент
xС ниже представляю центр фильтра для каждого выходного пикселя на входном изображении.x.x.x ..... x.x.x ..... x.x.x
и, конечно же, первое измерение ввода-это количество изображений, поэтому вы можете применить его к партии из 10 изображений, например:
input = tf.Variable(tf.random_normal([10,5,5,5])) filter = tf.Variable(tf.random_normal([3,3,5,7])) op = tf.nn.conv2d(input, filter, strides=[1, 2, 2, 1], padding='SAME')это выполняет ту же операцию, для каждого изображения независимо, давая стек из 10 изображений в результате (размер 10x3x3x7)
просто, чтобы добавить к другим ответам, вы должны думать параметров
filter = tf.Variable(tf.random_normal([3,3,5,7]))как '5' соответствует количеству каналов в каждом фильтре. Каждый фильтр представляет собой 3d куб, с глубиной 5. Глубина фильтра должна соответствовать глубине входного изображения. Последний параметр, 7, следует рассматривать как количество фильтров в пакете. Просто забудьте о том, что это 4D, и вместо этого представьте, что у вас есть набор или пакет из 7 фильтров. То, что вы делаете, это создать 7 кубов фильтра с Размеры (3,3,5).
это намного проще визуализировать в области Фурье, так как свертка становится точечным умножением. Для входного изображения размеров (100,100,3) вы можете переписать размеры фильтра как
filter = tf.Variable(tf.random_normal([100,100,3,7]))чтобы получить одну из 7 выходных карт объектов, мы просто выполняем точечное умножение Куба фильтра с кубом изображения, затем суммируем результаты по измерению каналов / глубины (здесь это 3), сворачиваясь в 2d (100,100) карте. Сделайте это с каждым кубом фильтра, и вы получите 7 2D карт объектов.
Я попытался реализовать conv2d (для моего изучения). Ну, я так и написал:
def conv(ix, w): # filter shape: [filter_height, filter_width, in_channels, out_channels] # flatten filters filter_height = int(w.shape[0]) filter_width = int(w.shape[1]) in_channels = int(w.shape[2]) out_channels = int(w.shape[3]) ix_height = int(ix.shape[1]) ix_width = int(ix.shape[2]) ix_channels = int(ix.shape[3]) filter_shape = [filter_height, filter_width, in_channels, out_channels] flat_w = tf.reshape(w, [filter_height * filter_width * in_channels, out_channels]) patches = tf.extract_image_patches( ix, ksizes=[1, filter_height, filter_width, 1], strides=[1, 1, 1, 1], rates=[1, 1, 1, 1], padding='SAME' ) patches_reshaped = tf.reshape(patches, [-1, ix_height, ix_width, filter_height * filter_width * ix_channels]) feature_maps = [] for i in range(out_channels): feature_map = tf.reduce_sum(tf.multiply(flat_w[:, i], patches_reshaped), axis=3, keep_dims=True) feature_maps.append(feature_map) features = tf.concat(feature_maps, axis=3) return featuresнадеюсь, что я сделал это правильно. Проверено на MNIST, были очень близкие результаты (но эта реализация медленнее). Я надеюсь, что это поможет вам.
в дополнение к другим ответам, операция conv2d работает на c++ (cpu) или cuda для gpu-машин, которые требуют сглаживания и изменения формы данных определенным образом и использования умножения матрицы gemmBLAS или cuBLAS(cuda).
Comments