Что такое граница слова в регулярных выражениях?
я использую Java regexes в Java 1.6 (в частности, для разбора числового вывода) и не могу найти точное определение b ("граница слова"). Я предполагал, что -12 будет "целое слово" (соответствует b-?d+b), но кажется, что это не работает. Я был бы благодарен узнать о способах сопоставления разделенных пробелами чисел.
пример:
Pattern pattern = Pattern.compile("s*b-?d+s*");
String plus = " 12 ";
System.out.println(""+pattern.matcher(plus).matches());
String minus = " -12 ";
System.out.println(""+pattern.matcher(minus).matches());
pattern = Pattern.compile("s*-?d+s*");
System.out.println(""+pattern.matcher(minus).matches());
возвращает:
true
false
true
10 ответов:
граница слова, в большинстве диалектов регулярных выражений, является положение между
\wи\W(Не-слово char), или в начале или конце строки, если она начинается или заканчивается (соответственно) с символа слова ([0-9A-Za-z_]).Итак, в строке
"-12", это будет соответствовать ДО 1 или после 2. Тире-это не символ слова.
граница слова может находиться в одной из трех позиций:
- перед первым символом в строке, если первый символ является символом слова.
- после последнего символа в строке, если последний символ является символом слова.
- между двумя символами в строке, где один является символом слова, а другой не является символом слова.
символы слова являются буквенно-цифровыми; знак минус-нет. Взято из Регулярное Выражение Учебник.
граница слова-это позиция, которая либо предшествует символу слова и не сопровождается одним, либо следует за символом слова и не предшествует одному.
ознакомьтесь с документацией по граничным условиям:
http://java.sun.com/docs/books/tutorial/essential/regex/bounds.html
проверить этот пример:
public static void main(final String[] args) { String x = "I found the value -12 in my string."; System.err.println(Arrays.toString(x.split("\b-?\d+\b"))); }когда вы распечатываете его, обратите внимание, что выход таков:
[Я нашел значение -в мою строку.]
это означает, что символ "-" не воспринимается как находящийся на границе слова, потому что он не считается символом слова. Похоже, @brianary вроде как опередил меня, поэтому он получает право голоса.
Я говорю о том, что
\b-границы регулярных выражений стиля на самом деле здесь.рассказ в том, что они условный. Их поведение зависит от того, что они рядом.
# same as using a \b before: (?(?=\w) (?<!\w) | (?<!\W) ) # same as using a \b after: (?(?<=\w) (?!\w) | (?!\W) )иногда это не то, что вы хотите. См. мой другой ответ для разработки.
я столкнулся с еще более серьезной проблемой при поиске текста для таких слов, как
.NET,C++,C#иC. Вы могли бы подумать, что компьютерные программисты будут знать лучше, чем называть язык, для которого трудно писать регулярные выражения.во всяком случае, это то, что я узнал (в основном изhttp://www.regular-expressions.info, что является отличным сайтом): в большинстве вариантов регулярных выражений символы, которые соответствуют короткой руке класс символов
\wсимволы, которые рассматриваются как символы слова по границам слов. Java является исключением. Java поддерживает Unicode для\bа не\w. (Я уверен, что в то время для этого была веская причина).The
\wозначает "символ слова". Он всегда соответствует символам ASCII[A-Za-z0-9_]. Обратите внимание на включение подчеркивания и цифр (но не тире!). В большинстве вкусов, которые поддерживают Unicode,\wвключает в себя множество персонажей из других файлы сценариев. Существует много несоответствий о том, какие символы на самом деле включены. Буквы и цифры из алфавитных сценариев и идеограмм, как правило, включены. Знаки препинания соединителя, отличные от подчеркивания и числовых символов, которые не являются цифрами, могут быть включены или не включены. XML-схема и XPath даже включают все символы в\w. Но Java, JavaScript и PCRE соответствуют только символам ASCII с\w.именно поэтому регулярное выражение на основе Java ищет
C++,C#или.NET(даже если вы помните, чтобы избежать периода и плюсы) облажались\b.примечание: Я не уверен, что с этим делать ошибки в тексте, например, когда кто-то не ставит пробел после точки в конце предложения. Я допускал это, но я не уверен, что это обязательно правильно.
в любом случае, в Java, если вы ищете текст для этих странных именованных языков, вам нужно заменить
\bдо и после пробельные символы и обозначения пунктуации. Например:public static String grep(String regexp, String multiLineStringToSearch) { String result = ""; String[] lines = multiLineStringToSearch.split("\n"); Pattern pattern = Pattern.compile(regexp); for (String line : lines) { Matcher matcher = pattern.matcher(line); if (matcher.find()) { result = result + "\n" + line; } } return result.trim(); }затем в тесте или основной функции:
String beforeWord = "(\s|\.|\,|\!|\?|\(|\)|\'|\\"|^)"; String afterWord = "(\s|\.|\,|\!|\?|\(|\)|\'|\\"|$)"; text = "Programming in C, (C++) C#, Java, and .NET."; System.out.println("text="+text); // Here is where Java word boundaries do not work correctly on "cutesy" computer language names. System.out.println("Bad word boundary can't find because of Java: grep with word boundary for .NET="+ grep("\b\.NET\b", text)); System.out.println("Should find: grep exactly for .NET="+ grep(beforeWord+"\.NET"+afterWord, text)); System.out.println("Bad word boundary can't find because of Java: grep with word boundary for C#="+ grep("\bC#\b", text)); System.out.println("Should find: grep exactly for C#="+ grep("C#"+afterWord, text)); System.out.println("Bad word boundary can't find because of Java:grep with word boundary for C++="+ grep("\bC\+\+\b", text)); System.out.println("Should find: grep exactly for C++="+ grep(beforeWord+"C\+\+"+afterWord, text)); System.out.println("Should find: grep with word boundary for Java="+ grep("\bJava\b", text)); System.out.println("Should find: grep for case-insensitive java="+ grep("?i)\bjava\b", text)); System.out.println("Should find: grep with word boundary for C="+ grep("\bC\b", text)); // Works Ok for this example, but see below // Because of the stupid too-short cutsey name, searches find stuff it shouldn't. text = "Worked on C&O (Chesapeake and Ohio) Canal when I was younger; more recently developed in Lisp."; System.out.println("text="+text); System.out.println("Bad word boundary because of C name: grep with word boundary for C="+ grep("\bC\b", text)); System.out.println("Should be blank: grep exactly for C="+ grep(beforeWord+"C"+afterWord, text)); // Make sure the first and last cases work OK. text = "C is a language that should have been named differently."; System.out.println("text="+text); System.out.println("grep exactly for C="+ grep(beforeWord+"C"+afterWord, text)); text = "One language that should have been named differently is C"; System.out.println("text="+text); System.out.println("grep exactly for C="+ grep(beforeWord+"C"+afterWord, text)); //Make sure we don't get false positives text = "The letter 'c' can be hard as in Cat, or soft as in Cindy. Computer languages should not require disambiguation (e.g. Ruby, Python vs. Fortran, Hadoop)"; System.out.println("text="+text); System.out.println("Should be blank: grep exactly for C="+ grep(beforeWord+"C"+afterWord, text));P. S. Моя спасибо http://regexpal.com/ без кого выражения мир был бы очень несчастен!
Я считаю, что ваша проблема связана с тем, что
-не является символом слова. Таким образом, граница слова будет совпадать после-, и поэтому не будет захватывать его. Границы слов совпадают перед первым и после последнего символа слова в строке, а также в любом месте, где перед ним находится символ слова или не-символ слова, а после него-наоборот. Также обратите внимание, что граница слова соответствует нулевой ширине.одна возможная альтернатива это
(?:(?:^|\s)-?)\d+\bэто будет соответствовать любым числам, начиная с пробела и необязательного тире, и заканчивая границей слова. Он также будет соответствовать числу, начиная с начала строки.
в ходе обучения регулярное выражение, я действительно застрял в метасимвол, которая составляет
\b. Я действительно не понимал его смысла, когда спрашивал себя:"что это такое, что это" повторно. После некоторых попыток с помощью сайте, Я наблюдаю за розовыми вертикальными черточками в каждом начале слов и в конце слов. Я хорошо понял его значение в то время. Это сейчас точно word (\w)-граница.мой взгляд просто чрезвычайно ориентирован на понимание. Логика за этим должна быть рассмотрена из других ответов.
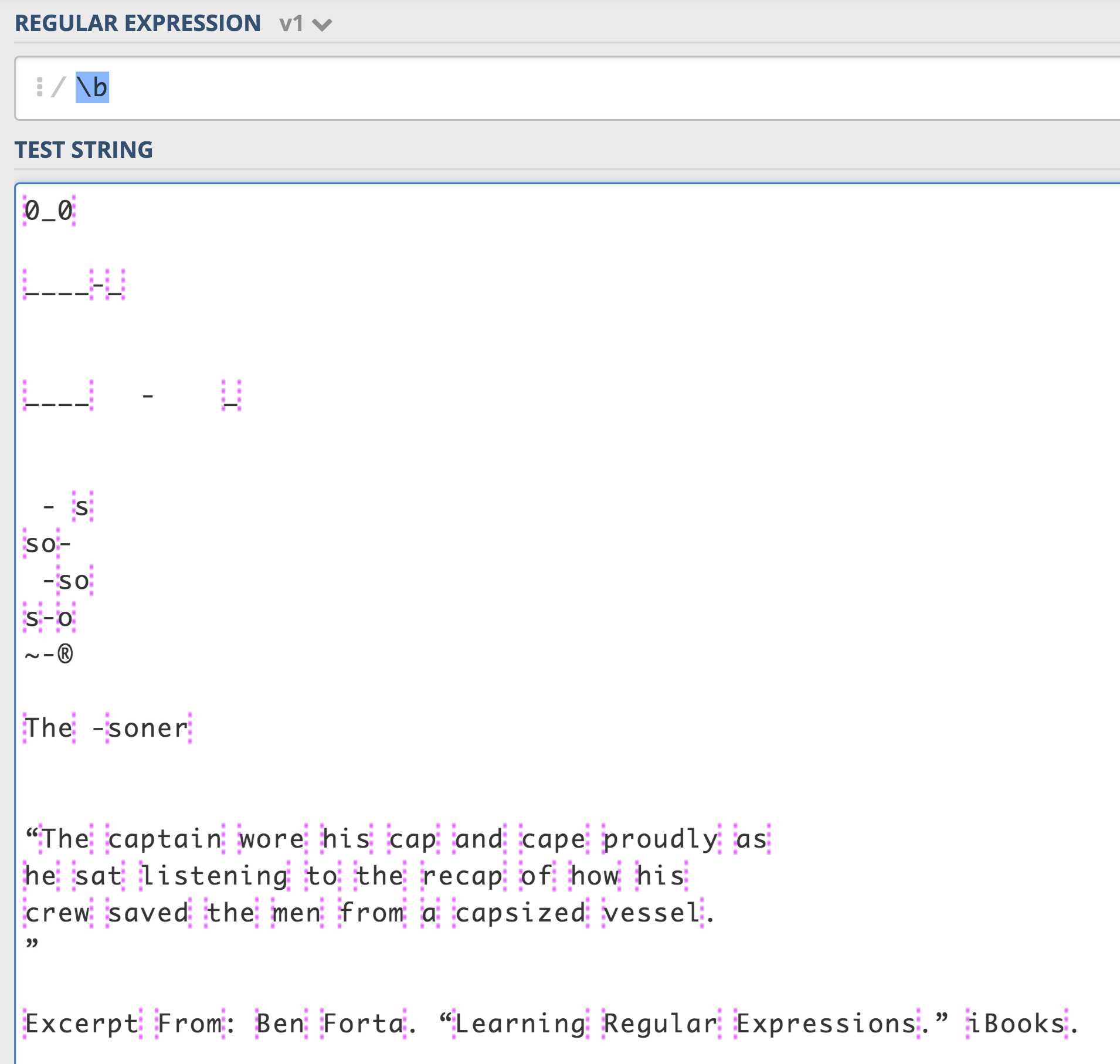
при использовании
\b(\w+)+\bЭто означает точное совпадение со словом, содержащим только символы слова([a-zA-Z0-9])в вашем случае, например, параметр
\bв начале регулярного выражения будет принимать-12(С пробелом), но опять же он не примет-12(без пробелов)для справки, чтобы поддержать мои слова:https://docs.oracle.com/javase/tutorial/essential/regex/bounds.html
Comments