Что логитов, softmax и softmax крест энтропии с логитов?
Я проходил через tensorflow API docs здесь. В tensorflow документации, они использовали ключевое слово, называемое logits. Что это? Во многих методах в документах API это написано как
tf.nn.softmax(logits, name=None)
если то, что написано-это те logits только Tensors, зачем держать другое имя, как logits?
другое дело, что есть два метода, которые я не мог различить. Они были
tf.nn.softmax(logits, name=None)
tf.nn.softmax_cross_entropy_with_logits(logits, labels, name=None)
каковы различия между ними? Документы мне не понятны. Я знаю, что tf.nn.softmax делает. Но не другой. Пример будет очень полезен.
5 ответов:
Logits просто означает, что функция работает на выходе без масштабирования более ранних слоев и что относительный масштаб для понимания единиц является линейным. Это означает, в частности, что сумма входных данных может не равняться 1, что значения не вероятности (у вас может быть вход 5).
tf.nn.softmaxпроизводит только результат применения функция softmax к входному тензору. Softmax "хлюпает" входы так, что сумма (вход) = 1; это способ нормализации. Форма вывода softmax такая же, как и на входе - она просто нормализует значения. Выходы softmax можете интерпретируются как вероятности.a = tf.constant(np.array([[.1, .3, .5, .9]])) print s.run(tf.nn.softmax(a)) [[ 0.16838508 0.205666 0.25120102 0.37474789]]в противоположность
tf.nn.softmax_cross_entropy_with_logitsвычисляет перекрестную энтропию результата после применения функции softmax (но он делает все это вместе более математически осторожным способом). Это похоже на результат:sm = tf.nn.softmax(x) ce = cross_entropy(sm)перекрестная энтропия является суммарной метрикой-it суммы по элементам. Выход
tf.nn.softmax_cross_entropy_with_logitsпо форме[2,5]тензор имеет форму[2,1](первый размер обрабатывается как пакет).если вы хотите сделать оптимизацию, чтобы минимизировать перекрестную энтропию, и вы softmaxing после вашего последнего слоя, вы должны использовать
tf.nn.softmax_cross_entropy_with_logitsвместо того, чтобы делать это самостоятельно, потому что он охватывает численно неустойчивые угловые случаи математически правильным образом. В противном случае вы в конечном итоге взломаете его, добавив сюда маленькие эпсилоны и там.(отредактировано 2016-02-07: если у вас есть метки одного класса, где объект может принадлежать только одному классу, теперь вы можете использовать
tf.nn.sparse_softmax_cross_entropy_with_logitsтак что вам не придется конвертировать ваши ярлыки к плотной горячей массива. Эта функция была добавлена после релиза 0.6.0.)
короткая версия:
предположим, что у вас есть два тензора, где
y_hatсодержит вычисленные оценки для каждого класса (например, от y = W*x +b) иy_trueсодержит одну горячую кодировку истинных меток.y_hat = ... # Predicted label, e.g. y = tf.matmul(X, W) + b y_true = ... # True label, one-hot encodedесли вы интерпретируете оценки в
y_hatкак ненормализованные логарифмические вероятности, то они логитов.кроме того, общая потеря перекрестной энтропии вычисляется следующим образом:
y_hat_softmax = tf.nn.softmax(y_hat) total_loss = tf.reduce_mean(-tf.reduce_sum(y_true * tf.log(y_hat_softmax), [1]))is по существу эквивалентно полной кросс-энтропийной потере, вычисленной с помощью функции
softmax_cross_entropy_with_logits():total_loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(y_hat, y_true))версия:
в выходном слое вашей нейронной сети вы, вероятно, вычислите массив, содержащий оценки классов для каждого из ваших учебных экземпляров, например, из вычисления
y_hat = W*x + b. Чтобы служить примером, ниже я создалy_hatкак массив 2 x 3, где строки соответствуют учебным экземплярам и столбцам соответствуют классам. Итак, здесь есть 2 учебных экземпляра и 3 класса.import tensorflow as tf import numpy as np sess = tf.Session() # Create example y_hat. y_hat = tf.convert_to_tensor(np.array([[0.5, 1.5, 0.1],[2.2, 1.3, 1.7]])) sess.run(y_hat) # array([[ 0.5, 1.5, 0.1], # [ 2.2, 1.3, 1.7]])обратите внимание, что значения не нормализованы (т. е. строки не складываются до 1). Чтобы нормализовать их, мы можем применить функцию softmax, которая интерпретирует входные данные как ненормализованные логарифмические вероятности (aka логитов) и выводит нормированные линейные вероятности.
y_hat_softmax = tf.nn.softmax(y_hat) sess.run(y_hat_softmax) # array([[ 0.227863 , 0.61939586, 0.15274114], # [ 0.49674623, 0.20196195, 0.30129182]])важно полностью понять, что говорит выход softmax. Ниже я показал таблица, которая более четко представляет результат выше. Можно видеть, что, например, вероятность того, что обучающий экземпляр 1 является "классом 2", равна 0,619. Вероятности классов для каждого обучающего экземпляра нормализованы, поэтому сумма каждой строки равна 1,0.
Pr(Class 1) Pr(Class 2) Pr(Class 3) ,-------------------------------------- Training instance 1 | 0.227863 | 0.61939586 | 0.15274114 Training instance 2 | 0.49674623 | 0.20196195 | 0.30129182Итак, теперь у нас есть вероятности классов для каждого экземпляра обучения, где мы можем взять argmax() каждой строки для создания окончательной классификации. Сверху мы можем сгенерировать, что обучающий экземпляр 1 относится к " классу 2" а обучающий экземпляр 2 относится к"классу 1".
верны ли эти классификации? Нам нужно измерить против истинных меток из тренировочного набора. Вам понадобится один-горячий кодированный
y_trueмассив, где снова строки являются учебными экземплярами, а столбцы-классами. Ниже я создал примерy_trueодин горячий массив, где истинная метка для обучающего экземпляра 1 - "класс 2", а истинная метка для обучающего экземпляра 2 - "класс 3".y_true = tf.convert_to_tensor(np.array([[0.0, 1.0, 0.0],[0.0, 0.0, 1.0]])) sess.run(y_true) # array([[ 0., 1., 0.], # [ 0., 0., 1.]])- это распределение вероятностей в
y_hat_softmaxблизко к распределению вероятности вy_true? Мы можем использовать кросс-энтропия потерь для измерения ошибок.
мы можем вычислить потери кросс-энтропии по строкам и посмотреть результаты. Ниже мы видим, что обучающий экземпляр 1 имеет потерю 0,479, в то время как обучающий экземпляр 2 имеет более высокую потерю 1,200. Этот результат имеет смысл, потому что в нашем примере выше,
y_hat_softmaxпоказала, что самая высокая вероятность обучения экземпляра 1 была для "класса 2", который соответствует учебному экземпляру 1 вy_true; однако прогноз для обучающего экземпляра 2 показал наибольшую вероятность для "класса 1", который не соответствует истинному классу"класс 3".loss_per_instance_1 = -tf.reduce_sum(y_true * tf.log(y_hat_softmax), reduction_indices=[1]) sess.run(loss_per_instance_1) # array([ 0.4790107 , 1.19967598])то, что мы действительно хотим, это полная потеря по всем учебным экземплярам. Таким образом, мы можем вычислить:
total_loss_1 = tf.reduce_mean(-tf.reduce_sum(y_true * tf.log(y_hat_softmax), reduction_indices=[1])) sess.run(total_loss_1) # 0.83934333897877944используя softmax_cross_entropy_with_logits()
вместо этого мы можем вычислить общая потеря перекрестной энтропии при использовании
tf.nn.softmax_cross_entropy_with_logits()функция, как показано ниже.loss_per_instance_2 = tf.nn.softmax_cross_entropy_with_logits(y_hat, y_true) sess.run(loss_per_instance_2) # array([ 0.4790107 , 1.19967598]) total_loss_2 = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(y_hat, y_true)) sess.run(total_loss_2) # 0.83934333897877922отметим, что
total_loss_1иtotal_loss_2дают по существу эквивалентные результаты с некоторыми небольшими различиями в самых последних цифрах. Однако вы можете также использовать второй подход: он занимает на одну строку меньше кода и накапливает меньше числовой ошибки, потому что softmax выполняется для вас внутриsoftmax_cross_entropy_with_logits().
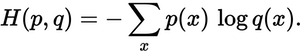
tf.nn.softmaxвычисляет прямое распространение через слой softmax. Вы используете его во время оценка модели при вычислении вероятностей, которые выводит модель.
tf.nn.softmax_cross_entropy_with_logitsвычисляет стоимость слоя softmax. Он используется только во время обучение.логиты-это ненормализованные логарифмические вероятности вывод модели (значения выводятся до применения к ним нормализации softmax).
выше ответы имеют достаточно описания для заданного вопроса.
добавляя к этому, Tensorflow оптимизировал операцию применения функции активации, а затем рассчитал стоимость, используя свою собственную активацию, за которой следуют функции стоимости. Поэтому это хорошая практика, чтобы использовать:
tf.nn.softmax_cross_entropy()overtf.nn.softmax(); tf.nn.cross_entropy()вы можете найти заметную разницу между ними в ресурсоемкой модели.
Logit-это функция, которая отображает вероятности [0, 1] в [-inf, +inf]. Tensorflow "with logit": это означает, что вы применяете функцию softmax к числам логита для его нормализации. Input_vector / logit не нормализуется и может масштабироваться из [-inf, inf].
такая нормализация используется для задач многоклассовой классификации. А для задач многоуровневой классификации используется нормализация сигмоиды т. е. tf.НН.sigmoid_cross_entropy_with_logits
Comments