Что такое шардинг и почему это важно?
Я думаю, что понимаю, что sharding возвращает ваши нарезанные данные (осколки) в простой в обращении агрегат, который имеет смысл в контексте. Это правильно?
обновление: Я думаю, что я борюсь здесь. На мой взгляд, уровень приложений не должен иметь никакого бизнеса, определяющего, где должны храниться данные. В лучшем случае это должен быть какой-то осколочный клиент. Оба ответа ответили на то, что, но не почему это важный аспект. Какие последствия это за пределами очевидного прироста производительности? Являются ли эти выгоды достаточными для компенсации нарушения MVC? Является ли сегментирование главным образом важным в очень крупномасштабных приложениях или оно применяется к более мелким масштабам?
6 ответов:
Sharding - это просто другое имя для "горизонтального разбиения" базы данных. Возможно, вы захотите найти этот термин, чтобы получить его более ясным.
С Википедия:
горизонтальное секционирование-это принцип проектирования, при котором строки таблицы базы данных хранятся отдельно, а не разбиваются по столбцам (как для нормализации). Каждый раздел является частью сегмента, который, в свою очередь, может быть расположен на отдельном сервере базы данных или в физическом расположении. Преимущество заключается в том, что количество строк в каждой таблице уменьшается (это уменьшает размер индекса, тем самым повышает производительность поиска). Если сегментация основана на некотором реальном аспекте данных (например, европейские клиенты против американских клиентов), то можно легко и автоматически вывести соответствующее членство в сегменте и запросить только соответствующий сегмент.
дополнительная информация о сегментировании:
во-первых, каждый сервер баз данных идентичны, имея ту же структуру таблицы. Во-вторых, записи данных логически разделяются в сегментированной базе данных. В отличие от секционированной базы данных, каждая полная запись данных существует только в одном сегменте (если нет зеркального отображения для резервного копирования/избыточности) со всеми операциями CRUD, выполняемыми только в этой базе данных. Возможно, Вам не нравится используемая терминология, но это представляет собой другой способ организации логической базы данных на более мелкие части.
обновление: вы не сломать MVC. Работа по определению правильного осколка, где хранить данные, будет прозрачно выполняться вашим уровнем доступа к данным. Там вам нужно будет определить правильный сегмент на основе критериев, которые вы использовали для сегментации своей базы данных. (Как вы должны вручную разбить базу данных на несколько различных осколков на основе некоторых конкретных аспектов вашего приложения.) Затем вы должны заботиться при загрузке и хранении данных из/в базу данных, чтобы использовать правильный осколок.
может С кодом Java делает его несколько яснее (речь идет о Hibernate Shards), как это будет работать в реальной ситуации.
в адрес "
why sharding": Это, в основном, только для очень больших приложений, с много данных. Во-первых, это помогает минимизировать время отклика на запросы к базе данных. Во-вторых, вы можете использовать более дешевые, "нижние" машины для размещения ваших данных вместо одного большого сервера, который может не хватит уже.
Если у вас есть запросы к СУБД, для которых локальность довольно ограничена (скажем, пользователь только запускает выбор с помощью "where username = $my_username"), имеет смысл поместить все имена пользователей, начинающиеся с A-M, на одном сервере и все из N-Z на другом. Таким образом, вы приближаетесь к линейному масштабированию для некоторых запросов.
короче: Sharding-это в основном процесс распределения таблиц на разных серверах, чтобы сбалансировать нагрузку на оба сервера в равной степени.
конечно, на самом деле все гораздо сложнее. :)
является сегментирование главное в очень крупномасштабные приложения или применить к более мелким масштабам?
Sharding является проблемой тогда и только тогда, когда ваши потребности масштабируются мимо того, что может обслуживаться одним сервером базы данных. Это отличный инструмент, если у вас есть сегментируемые данные, и у вас невероятно высокие требования к масштабируемости и производительности. Я бы предположил, что за все мои 12 лет я был профессионалом в области программного обеспечения, я столкнулся с одной ситуацией, которая могла бы иметь выиграли от осколков. Это передовой метод с очень ограниченной применимостью.
кроме того, будущее, вероятно, будет чем-то веселым и захватывающим, как массивный объект "облако", которое стирает все потенциальные ограничения производительности, не так ли? :)
Sharding был первоначально придуман инженерами google, и вы можете видеть, что он используется довольно сильно при написании приложений на Google App Engine. Поскольку существуют жесткие ограничения на количество ресурсов, которые могут использовать ваши запросы, и поскольку сами запросы имеют строгие ограничения, сегментирование не только поощряется, но и почти принудительно применяется архитектурой.
еще одно место, где можно использовать сегментацию, - это уменьшить конкуренцию на объектах данных. Это особенно важно при строительстве масштабируемые системы должны следить за теми фрагментами данных, которые часто записываются, потому что они всегда являются узким местом. Хорошим решением является осколок этого конкретного объекта и запись в несколько копий, а затем чтение итога. Пример этого " шарообразного счетчика wrt GAE:http://code.google.com/appengine/articles/sharding_counters.html
сегментирования является горизонтальной( row wise) разделение базы данных в отличие от вертикального (столбец мудрый) перегородки, которая нормализация. Он разделяет очень большие базы данных на более мелкие, быстрые и легко управляемые части, называемые фрагментами данных. Это механизм для достижения распределенных систем.
зачем нам нужны распределенные системы?
- увеличить доступность.
- легче расширение.
- экономика: это стоит меньше, чтобы создать сеть небольших компьютеров с мощностью одного большого компьютера.
вы можете прочитать здесь: преимущества распределенной базы данных
Как сегментирование помогает достичь распределенной системы?
вы можете разбить индекс поиска на N разделов и загрузить каждый индекс на отдельном сервере. Если вы запросите один сервер, вы получите 1/Nth результатов. Итак, чтобы получить полный набор результатов, типичная распределенная поисковая система использует агрегатор это будет накапливать результаты с каждого сервера и объединять их. Агрегатор также распределяет запрос на каждый сервер. Эта программа-агрегатор называется MapReduce в терминологии больших данных. Другими словами, распределенные системы = Sharding + MapReduce (хотя есть и другие вещи).
визуальное представление ниже.
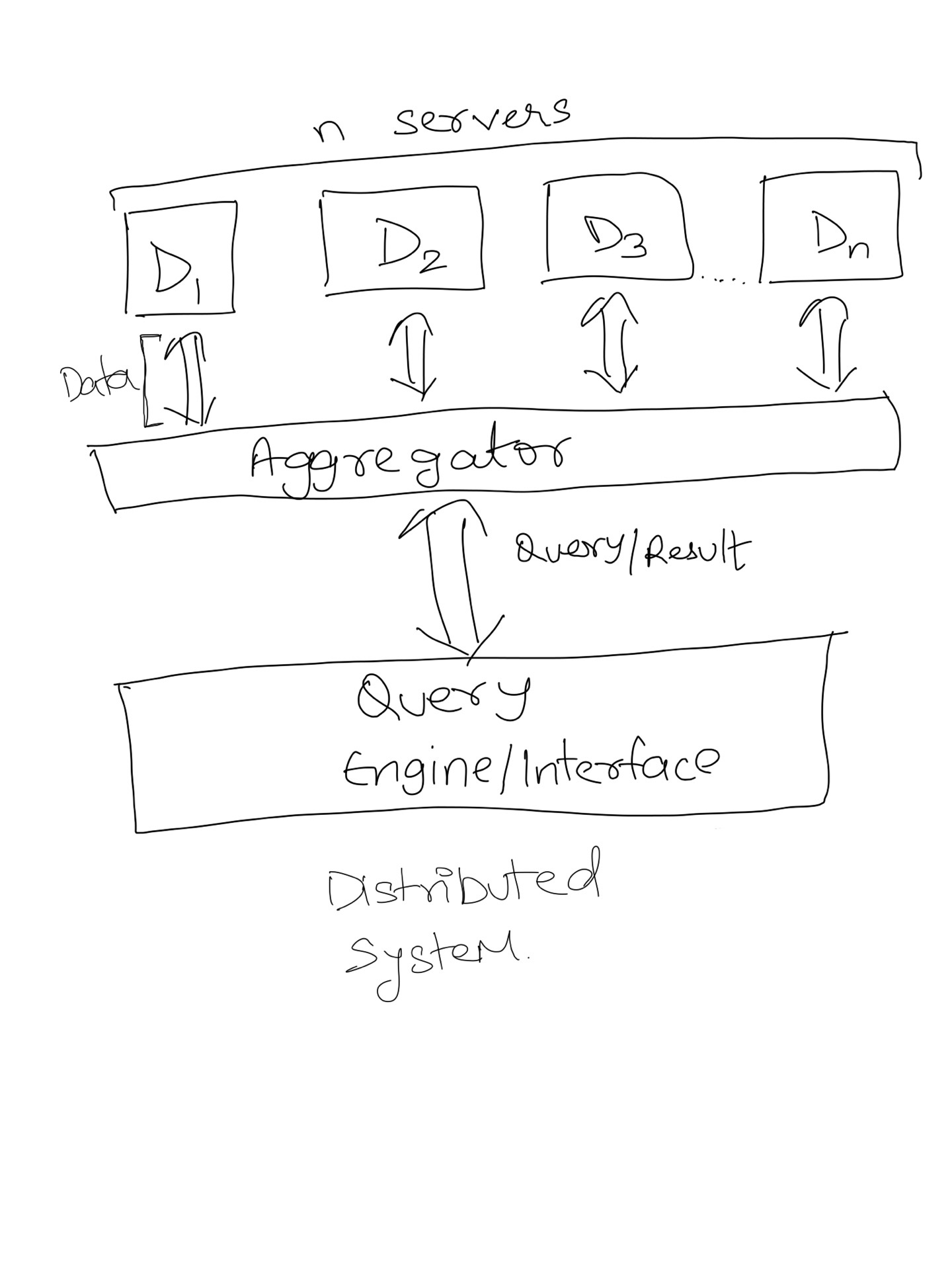
на мой взгляд уровень приложений не должно иметь никакого бизнеса определения где должны храниться данные
Это хорошее правило, но как и большинство вещей не всегда правильно.
когда вы делаете свою архитектуру, вы начинаете с ответственности и сотрудничества. Как только вы определяете свою функциональную архитектуру, вы должны сбалансировать нефункциональные силы.
если одна из этих нефункциональных сил является массивной масштабируемостью, вы должны адаптируйте свою архитектуру для удовлетворения этой силы, даже если это означает, что ваша абстракция хранения данных теперь просачивается на ваш уровень приложений.
Comments