Каков наиболее эффективный способ нахождения всех факторов числа в Python?
может ли кто-нибудь объяснить мне эффективный способ нахождения всех факторов числа в Python (2.7)?
Я могу создавать алгоритмы для выполнения этой работы, но я думаю, что она плохо закодирована и занимает слишком много времени для выполнения результата для больших чисел.
19 ответов:
from functools import reduce def factors(n): return set(reduce(list.__add__, ([i, n//i] for i in range(1, int(n**0.5) + 1) if n % i == 0)))это вернет все факторы, очень быстро, ряд
n.почему квадратный корень как верхний предел?
sqrt(x) * sqrt(x) = x. Поэтому, если два фактора одинаковы, они оба являются квадратным корнем. Если вы делаете один фактор больше, вы должны сделать другой фактор меньше. Это означает, что один из двух всегда будет меньше чем или равноsqrt(x), Так что вам нужно только искать до этого момента, чтобы найти один из двух совпадающих факторов. Затем вы можете использоватьx / fac1иfac2.The
reduce(list.__add__, ...)берет маленькие списки[fac1, fac2]и соединяя их вместе в один длинный список.The
[i, n/i] for i in range(1, int(sqrt(n)) + 1) if n % i == 0возвращает пару факторов, если остаток при деленииnменьший равен нулю (ему не нужно проверять и больший; он просто получает это, разделяяnпо меньшей.)The
set(...)снаружи избавляется от дубликатов, что происходит только для идеальных квадратов. Дляn = 4, это вернет2два раза, такsetизбавляется от одного из них.
решение, представленное @agf, отлично, но можно достичь ~50% более быстрого времени выполнения для произвольного странно числа путем проверки на четность. Поскольку факторы нечетного числа всегда сами по себе нечетны, нет необходимости проверять их при работе с нечетными числами.
Я только начал решать Проект Эйлера пазлы сам. В некоторых задачах проверка делителя вызывается внутри двух вложенных
forпетли, и производительность этой функции таким образом существенный.объединив этот факт с отличным решением agf, я закончил с этой функцией:
from math import sqrt def factors(n): step = 2 if n%2 else 1 return set(reduce(list.__add__, ([i, n//i] for i in range(1, int(sqrt(n))+1, step) if n % i == 0)))однако при малых числах (~
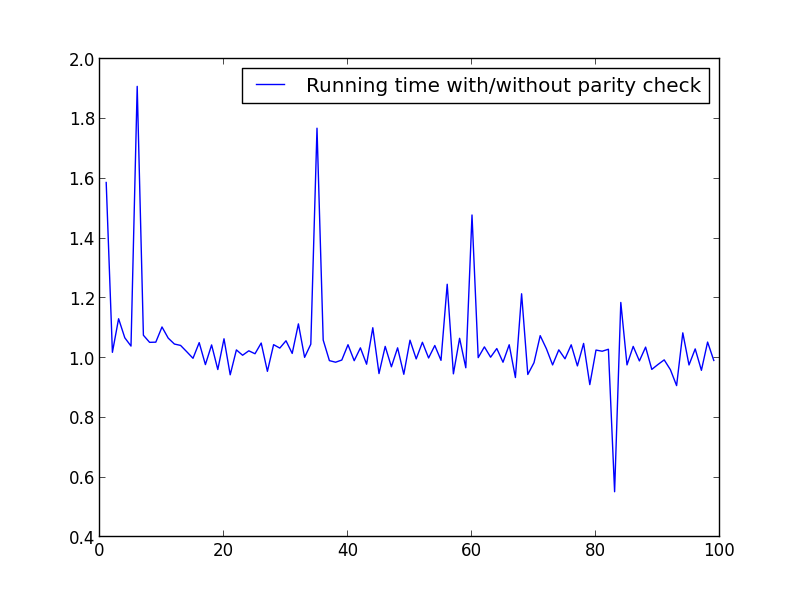
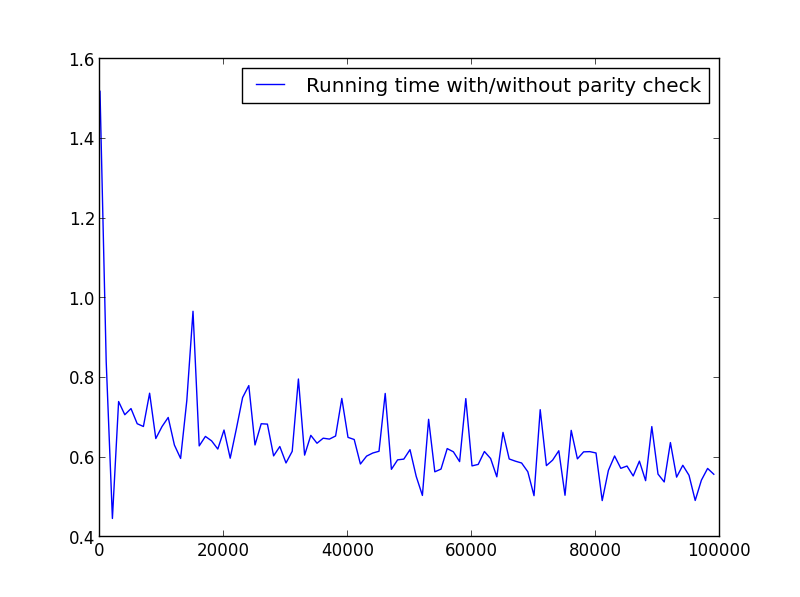
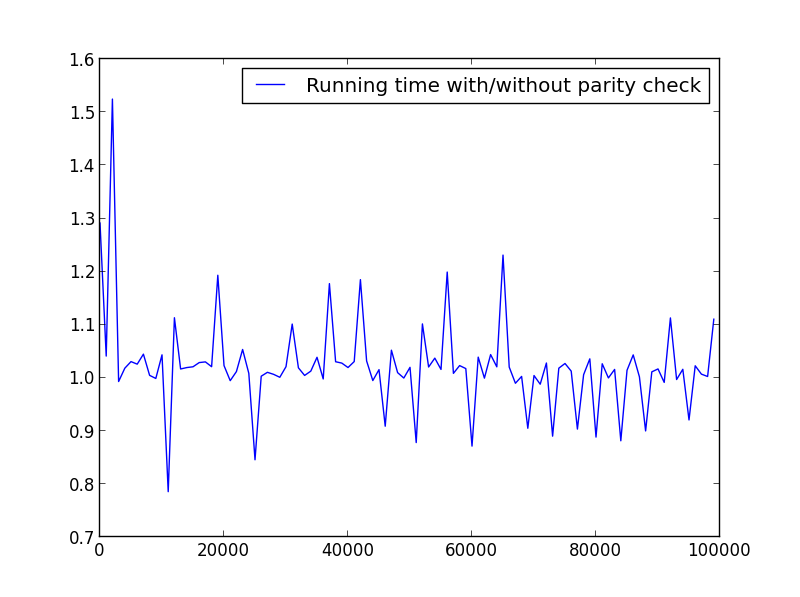
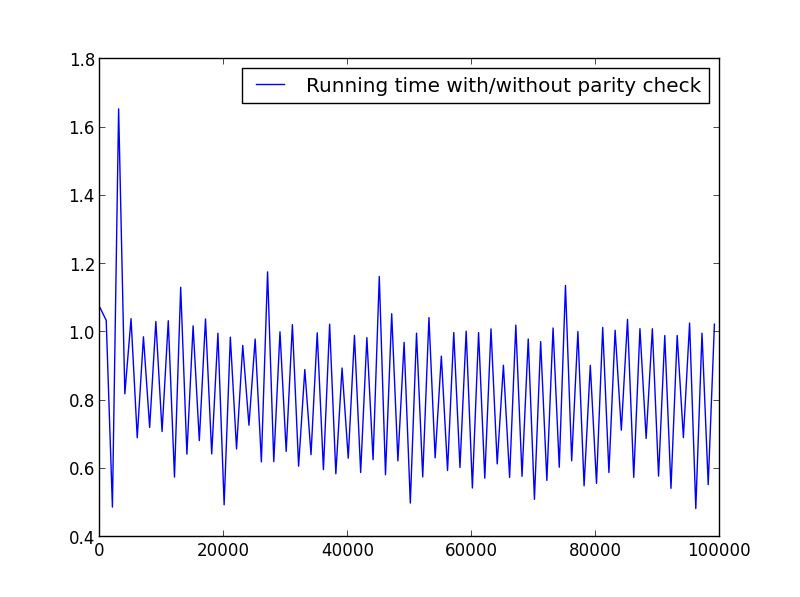
Я провел несколько тестов, чтобы проверить скорость. Ниже приведен используемый код. Чтобы создать различные сюжеты, я изменил
X = range(1,100,1)соответственно.import timeit from math import sqrt from matplotlib.pyplot import plot, legend, show def factors_1(n): step = 2 if n%2 else 1 return set(reduce(list.__add__, ([i, n//i] for i in range(1, int(sqrt(n))+1, step) if n % i == 0))) def factors_2(n): return set(reduce(list.__add__, ([i, n//i] for i in range(1, int(sqrt(n)) + 1) if n % i == 0))) X = range(1,100000,1000) Y = [] for i in X: f_1 = timeit.timeit('factors_1({})'.format(i), setup='from __main__ import factors_1', number=10000) f_2 = timeit.timeit('factors_2({})'.format(i), setup='from __main__ import factors_2', number=10000) Y.append(f_1/f_2) plot(X,Y, label='Running time with/without parity check') legend() show()X = диапазон(1,100,1)
здесь нет существенной разницы, но с большими числами преимущество очевидно:
X = диапазон (1,100000,1000) (только нечетные числа)
X = диапазон (2,100000,100) (только четные числа)
X = диапазон (1,100000,1001) (переменная четность)
ответ agf действительно довольно крут. Я хотел посмотреть, смогу ли я переписать его, чтобы избежать использования
reduce(). Вот что я придумал:import itertools flatten_iter = itertools.chain.from_iterable def factors(n): return set(flatten_iter((i, n//i) for i in range(1, int(n**0.5)+1) if n % i == 0))Я также попробовал версию, которая использует сложные функции генератора:
def factors(n): return set(x for tup in ([i, n//i] for i in range(1, int(n**0.5)+1) if n % i == 0) for x in tup)Я рассчитал путем расчета:
start = 10000000 end = start + 40000 for n in range(start, end): factors(n)Я запустил его один раз, чтобы позволить Python скомпилировать его, а затем запустил его под командой time(1) три раза и сохранил лучшее время.
- уменьшения версию: 11.58 секунды
- версия itertools: 11.49 секунд
- хитрая версия: 11.12 секунд
обратите внимание, что версия itertools создает кортеж и передает его в flatten_iter(). Если я изменю код, чтобы построить список вместо этого, он немного замедляется:
- iterools (список) версия: 11.62 секунд
Я считаю, что версия сложных функций генератора является самой быстрой в Python. Но это не совсем так гораздо быстрее, чем уменьшенная версия, примерно на 4% быстрее, основываясь на моих измерениях.
альтернативный подход, чтобы ответить на это:
def factors(n): result = set() for i in range(1, int(n ** 0.5) + 1): div, mod = divmod(n, i) if mod == 0: result |= {i, div} return result
дальнейшее улучшение решения afg & eryksun. Следующий фрагмент кода возвращает сортированный список всех факторов без изменения асимптотической сложности времени выполнения:
def factors(n): l1, l2 = [], [] for i in range(1, int(n ** 0.5) + 1): q,r = n//i, n%i # Alter: divmod() fn can be used. if r == 0: l1.append(i) l2.append(q) # q's obtained are decreasing. if l1[-1] == l2[-1]: # To avoid duplication of the possible factor sqrt(n) l1.pop() l2.reverse() return l1 + l2идея: вместо использования списка.функция sort () для получения отсортированного списка, который дает сложность nlog(n); гораздо быстрее использовать список.обратный () на l2, который принимает o(n) сложность. (Вот как делается python.) После Л2.reverse (), l2 может быть добавлен к l1 для получения отсортированного списка факторы.
обратите внимание, l1 содержит Я - s, которые увеличиваются. l2 содержит q - s, которые уменьшаются. Вот причина использования вышеуказанной идеи.
Я пробовал большинство из этих замечательных ответов с timeit, чтобы сравнить их эффективность с моей простой функцией, и все же я постоянно вижу, что мои превосходят перечисленные здесь. Я решил поделиться им и посмотреть, что вы все думаете.
def factors(n): results = set() for i in xrange(1, int(math.sqrt(n)) + 1): if n % i == 0: results.add(i) results.add(int(n/i)) return resultsКак написано, вам придется импортировать математику для тестирования, но заменить математику.sqrt (n) с n**.5 должен работать так же хорошо. Я не трачу время на проверку дубликатов, потому что дубликаты не могут существовать в наборе независимо.
вот альтернатива решению @agf, которое реализует тот же алгоритм в более питоническом стиле:
def factors(n): return set( factor for i in range(1, int(n**0.5) + 1) if n % i == 0 for factor in (i, n//i) )Это решение работает как в Python 2, так и в Python 3 без импорта и гораздо более читаемо. Я не проверял производительность этого подхода, но асимптотически она должна быть одинаковой, и если производительность является серьезной проблемой, ни одно из решений не является оптимальным.
существует алгоритм отраслевой прочности в SymPy называется factorint:
>>> from sympy import factorint >>> factorint(2**70 + 3**80) {5: 2, 41: 1, 101: 1, 181: 1, 821: 1, 1597: 1, 5393: 1, 27188665321L: 1, 41030818561L: 1}это заняло меньше минуты. Он переключается между коктейлем методов. См. документацию, связанную выше.
учитывая все основные факторы, все остальные факторы могут быть легко построены.
обратите внимание, что даже если принятый ответ был разрешен достаточно долго (т. е. вечность), чтобы разложить на множители вышеуказанное число, для некоторых больших чисел он потерпит неудачу, например следующий пример. Это из-за небрежности
int(n**0.5). Например, когдаn = 10000000000000079**2, мы>>> int(n**0.5) 10000000000000078LС 10000000000000079 является простым, алгоритм принятого ответа никогда не найдет этот фактор. Обратите внимание, что это не просто off-by-one; для больших чисел он будет выключен больше. По этой причине лучше избегать чисел с плавающей точкой в алгоритмах такого рода.
вот еще один альтернативный без уменьшения, который хорошо работает с большими числами. Он использует
sumчтобы развернуть список.def factors(n): return set(sum([[i, n//i] for i in xrange(1, int(n**0.5)+1) if not n%i], []))
обязательно возьмите число больше, чем
sqrt(number_to_factor)для необычных чисел, таких как 99, которые имеют 3*3*11 иfloor sqrt(99)+1 == 10.import math def factor(x): if x == 0 or x == 1: return None res = [] for i in range(2,int(math.floor(math.sqrt(x)+1))): while x % i == 0: x /= i res.append(i) if x != 1: # Unusual numbers res.append(x) return res
для n до 10* * 16 (может быть, даже немного больше), вот быстрое чистое решение Python 3.6,
from itertools import compress def primes(n): """ Returns a list of primes < n for n > 2 """ sieve = bytearray([True]) * (n//2) for i in range(3,int(n**0.5)+1,2): if sieve[i//2]: sieve[i*i//2::i] = bytearray((n-i*i-1)//(2*i)+1) return [2,*compress(range(3,n,2), sieve[1:])] def factorization(n): """ Returns a list of the prime factorization of n """ pf = [] for p in primeslist: if p*p > n : break count = 0 while not n % p: n //= p count += 1 if count > 0: pf.append((p, count)) if n > 1: pf.append((n, 1)) return pf def divisors(n): """ Returns an unsorted list of the divisors of n """ divs = [1] for p, e in factorization(n): divs += [x*p**k for k in range(1,e+1) for x in divs] return divs n = 600851475143 primeslist = primes(int(n**0.5)+1) print(divisors(n))
вот пример, если вы хотите использовать простое число, чтобы идти намного быстрее. Эти списки легко найти в интернете. Я добавил комментарии в коде.
# http://primes.utm.edu/lists/small/10000.txt # First 10000 primes _PRIMES = (2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97, 101, 103, 107, 109, 113, 127, 131, 137, 139, 149, 151, 157, 163, 167, 173, 179, 181, 191, 193, 197, 199, 211, 223, 227, 229, 233, 239, 241, 251, 257, 263, 269, 271, 277, 281, 283, 293, 307, 311, 313, 317, 331, 337, 347, 349, 353, 359, 367, 373, 379, 383, 389, 397, 401, 409, 419, 421, 431, 433, 439, 443, 449, 457, 461, 463, 467, 479, 487, 491, 499, 503, 509, 521, 523, 541, 547, 557, 563, 569, 571, 577, 587, 593, 599, 601, 607, 613, 617, 619, 631, 641, 643, 647, 653, 659, 661, 673, 677, 683, 691, 701, 709, 719, 727, 733, 739, 743, 751, 757, 761, 769, 773, 787, 797, 809, 811, 821, 823, 827, 829, 839, 853, 857, 859, 863, 877, 881, 883, 887, 907, 911, 919, 929, 937, 941, 947, 953, 967, 971, 977, 983, 991, 997, 1009, 1013, # Mising a lot of primes for the purpose of the example ) from bisect import bisect_left as _bisect_left from math import sqrt as _sqrt def get_factors(n): assert isinstance(n, int), "n must be an integer." assert n > 0, "n must be greather than zero." limit = pow(_PRIMES[-1], 2) assert n <= limit, "n is greather then the limit of {0}".format(limit) result = set((1, n)) root = int(_sqrt(n)) primes = [t for t in get_primes_smaller_than(root + 1) if not n % t] result.update(primes) # Add all the primes factors less or equal to root square for t in primes: result.update(get_factors(n/t)) # Add all the factors associted for the primes by using the same process return sorted(result) def get_primes_smaller_than(n): return _PRIMES[:_bisect_left(_PRIMES, n)]
используя
set(...)делает код немного медленнее, и это действительно необходимо только при проверке квадратного корня. Вот моя версия:def factors(num): if (num == 1 or num == 0): return [] f = [1] sq = int(math.sqrt(num)) for i in range(2, sq): if num % i == 0: f.append(i) f.append(num/i) if sq > 1 and num % sq == 0: f.append(sq) if sq*sq != num: f.append(num/sq) return fThe
if sq*sq != num:условие является необходимым для числа 12, где квадратный корень не является целым числом, но пол квадратного корня является фактором.обратите внимание, что эта версия не возвращает само число, но это легко исправить, если вы этого хотите. Вывод также не сортируется.
я приурочил его работает 10000 раз на все числа 1-200 и 100 раз на все числа 1-5000. Он превосходит все другие версии, которые я тестировал, включая решения dansalmo, Jason Schorn, oxrock, agf, steveha и eryksun, хотя oxrock на сегодняшний день является самым близким.
Используйте что-то простое, как следующее понимание списка, отмечая, что нам не нужно проверять 1 и число, которое мы пытаемся найти:
def factors(n): return [x for x in range(2, n//2+1) if n%x == 0]в отношении использования квадратного корня, скажем, мы хотим найти коэффициенты 10. Целочисленная часть
range(1, int(sqrt(10))) = [1, 2, 3, 4]и тестирование до 4 явно пропускает 5.если я не упускаю что-то я бы предложил, если вы должны сделать это таким образом, используя
int(ceil(sqrt(x))). Конечно, это производит много ненужного вызовы функций.
потенциально более эффективный алгоритм, чем те, которые уже представлены здесь (особенно если в
n). фокус здесь в том, чтобы настройка предела до которого пробное разделение необходимо каждый раз, когда простые множители найдены:def factors(n): ''' return prime factors and multiplicity of n n = p0^e0 * p1^e1 * ... * pk^ek encoded as res = [(p0, e0), (p1, e1), ..., (pk, ek)] ''' res = [] # get rid of all the factors of 2 using bit shifts mult = 0 while not n & 1: mult += 1 n >>= 1 if mult != 0: res.append((2, mult)) limit = round(sqrt(n)) test_prime = 3 while test_prime <= limit: mult = 0 while n % test_prime == 0: mult += 1 n //= test_prime if mult != 0: res.append((test_prime, mult)) if n == 1: # only useful if ek >= 3 (ek: multiplicity break # of the last prime) limit = round(sqrt(n)) # adjust the limit test_prime += 2 # will often not be prime... if n != 1: res.append((n, 1)) return resэто, конечно, все еще судебный отдел и ничего более причудливого. и поэтому все еще весьма ограничены в своей эффективности (особенно для больших чисел без делителей).
это питон3; отдел
//должно быть единственное, что вам нужно адаптировать для Python 2 (Добавитьfrom __future__ import division).
Я думаю, что для читаемости и скорости решение @oxrock является лучшим, поэтому вот код, переписанный для python 3+:
def num_factors(n): results = set() for i in range(1, int(n**0.5) + 1): if n % i == 0: results.update([i,int(n/i)]) return results
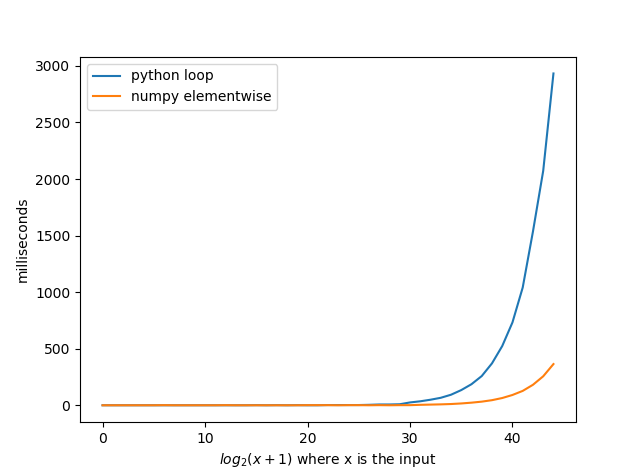
Я был очень удивлен, когда увидел этот вопрос, что никто не использовал numpy, даже когда numpy быстрее чем петли python. Реализовав решение @agf с помощью numpy и получилось в среднем в 8 раз быстрее. Я считаю, что если бы вы реализовали некоторые другие решения в numpy, вы могли бы получить удивительные времена.
вот моя функция:
import numpy as np def b(n): r = np.arange(1, int(n ** 0.5) + 1) x = r[np.mod(n, r) == 0] return set(np.concatenate((x, n / x), axis=None))обратите внимание, что номера оси x не являются входными данными для функций. Вход функции-это 2 к числу на оси x минус 1. Итак, где десять вход будет 2* * 10-1 = 1023
без использования функции reduce (), которая не является встроенной функцией в Python3:
def factors(n): res = [f(x) for f in (lambda x: x, lambda x: n // x) for x in range(1, int(n**0.5) + 1) if not n % x] return set(res) # returns a set to remove the duplicates from res
Я считаю, что это самый простой способ сделать это:
x = 23 i = 1 while i <= x: if x % i == 0: print("factor: %s"% i) i += 1
Comments