Какова связь между количеством опорных векторов и показателями обучающих данных и классификаторов?
Я использую LibSVM для классификации некоторых документов. Документы, кажется,немного трудно классифицировать, как показывают окончательные результаты. Тем не менее, я заметил кое-что во время обучения моих моделей. и это: если мой набор обучения, например, 1000 около 800 из них выбраны в качестве векторов поддержки.
Я искал везде, чтобы найти, если это хорошо или плохо. Я имею в виду, существует ли связь между количеством опорных векторов и производительностью классификаторов?
Я читал этот пост ранее должность. Тем не менее, я выполняю выбор параметров, а также уверен, что атрибуты в векторах объектов упорядочены.
Мне просто нужно знать отношение.
Спасибо.
С. с: я использую линейные ядра.
5 ответов:
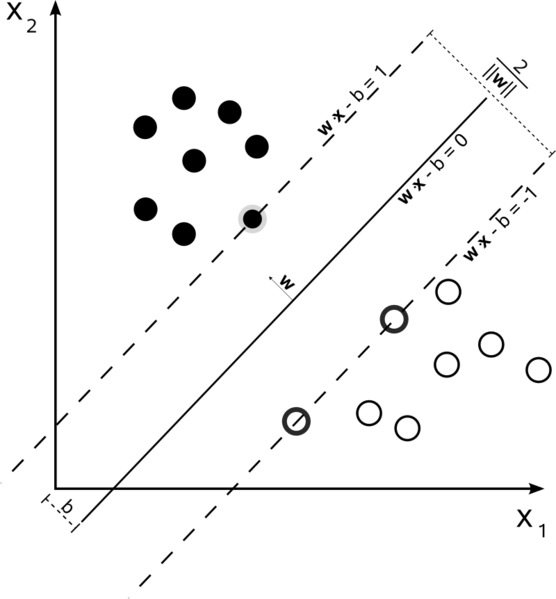
поддержка векторных машин является проблемой оптимизации. Они пытаются найти гиперплоскость, которая делит два класса с наибольшим запасом. Опорные векторы-это точки, которые попадают в это поле. Это проще всего понять, если вы строите его от простого к более сложному.
Hard Margin Linear SVM
в обучающем наборе, где данные линейно разделимы, и вы используете жесткий запас (не допускается слабина), поддержка векторы-это точки, лежащие вдоль опорных гиперплоскостей (гиперплоскостей, параллельных разделительной гиперплоскости по краям поля)
все опорные векторы лежат точно на полях. Независимо от количества измерений или размера набора данных, число опорных векторов может быть всего 2.
Soft-Margin Linear SVM
но что, если наш набор данных не линейно отделимые? Мы представляем мягкий запас SVM. Мы больше не требуем, чтобы наши точки данных лежали за пределами поля, мы позволяем некоторому их количеству отклоняться от линии в поле. Мы используем параметр slack C для управления этим. (nu в nu-SVM) это дает нам более широкий запас и большую ошибку в обучающем наборе данных, но улучшает обобщение и/или позволяет нам найти линейное разделение данных, которое не является линейно разделяемым.
сейчас, количество опорных векторов зависит от того, сколько слабину мы допускаем и при распределении данных. Если мы допустим большое количество провисания, у нас будет большое количество опорных векторов. Если мы допустим очень мало слабины, у нас будет очень мало опорных векторов. Точность зависит от нахождения правильного уровня слабины для анализируемых данных. Некоторые данные не удастся получить высокий уровень точности, мы должны просто найти наилучшее соответствие мы можем.
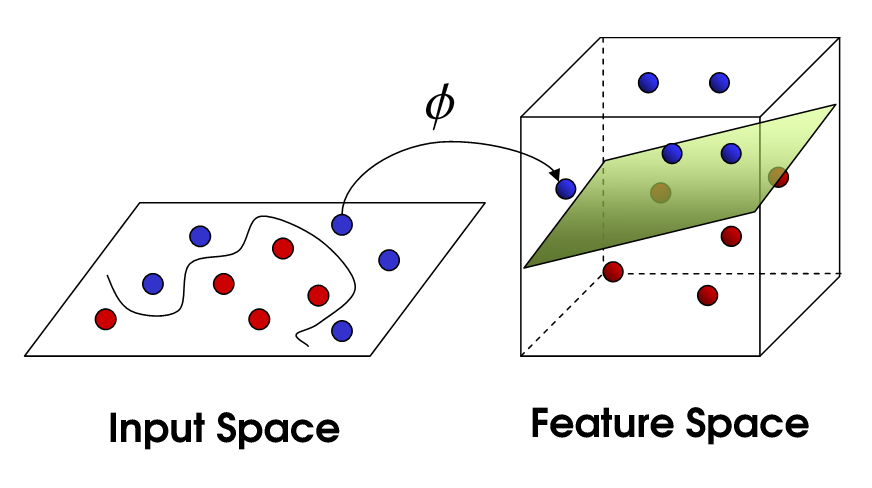
нелинейный SVM
Это приводит нас к нелинейному SVM. Мы все еще пытаемся линейно разделить данные, но теперь мы пытаемся сделать это в более высоком размерном пространстве. Это делается с помощью функции ядра, которая, конечно же, имеет свой собственный набор параметров. Когда мы переводим это обратно в исходное пространство объектов, результат будет нелинейным:
теперь количество опорных векторов все еще зависит от того, насколько мы допускаем слабину, но это также зависит от сложности нашей модели. Каждый поворот и поворот в окончательной модели в нашем для определения пространства ввода требуется один или несколько опорных векторов. В конечном счете, выход SVM-это опорные векторы и Альфа, которые, по сути, определяют, насколько сильно этот конкретный опорный вектор влияет на окончательное решение.
здесь точность зависит от компромисса между моделью высокой сложности, которая может чрезмерно соответствовать данным, и большим запасом, который будет неправильно классифицировать некоторые данные обучения в интересах лучшего обобщения. Количество поддержки векторы могут варьироваться от очень немногих до каждой отдельной точки данных, если вы полностью перекрываете свои данные. Этот компромисс управляется через C и через выбор ядра и параметров ядра.
Я предполагаю, что когда вы сказали производительность, вы имели в виду точность, но я думал, что буду также говорить о производительности с точки зрения вычислительной сложности. Чтобы проверить точку данных с помощью модели SVM, необходимо вычислить точечное произведение каждого опорного вектора с тестовой точкой. Следовательно вычислительная сложность модели линейна по числу опорных векторов. Меньшее количество опорных векторов означает более быструю классификацию тестовых точек.
хороший ресурс: учебник по поддержке векторных машин для распознавания образов
800 из 1000 в основном говорит вам, что SVM должен использовать почти каждый обучающий образец для кодирования обучающего набора. Это в основном говорит вам, что нет закономерности в ваших данных.
похоже, у тебя серьезные проблемы с недостаточным количеством данных для обучения. Кроме того, возможно, подумайте о некоторых конкретных особенностях, которые лучше разделяют эти данные.
и количество образцов и количество атрибутовмая влияет на количество опорных векторов, делая модель более сложной. Я считаю, что вы используете слова или даже ngrams в качестве атрибутов, поэтому их довольно много, и модели естественного языка сами по себе очень сложны. Таким образом, 800 опорных векторов из 1000 образцов, похоже, в порядке. (Также обратите внимание на комментарии @karenu о параметрах C / nu, которые также оказывают большое влияние на SVs число.)
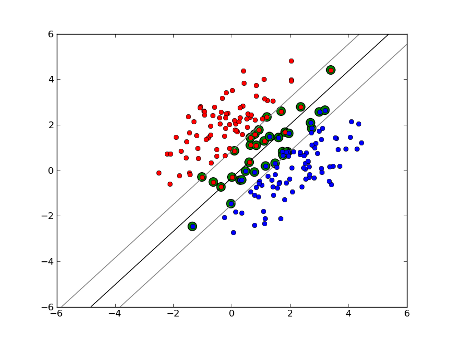
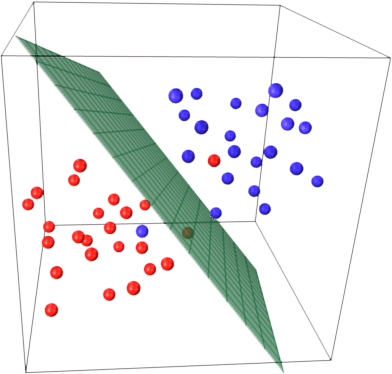
чтобы получить интуицию об этом, вспомните основную идею SVM. SVM работает в многомерном пространстве и пытается найти гиперплоскость это разделяет все заданные образцы. Если у вас есть много образцов и только 2 объекта (2 измерения), данные и гиперплоскость могут выглядеть следующим образом:
здесь есть только 3 вектора поддержки, все остальные находятся за ними и, таким образом, не играют никакой роли. Обратите внимание, что эти поддержки векторы определяются только двумя координатами.
теперь представьте, что у вас есть 3-мерное пространство и, таким образом, опорные векторы определяются 3 координатами.
Это означает, что необходимо настроить еще один параметр (координату), и для этой настройки может потребоваться больше выборок, чтобы найти оптимальную гиперплоскость. Другими словами, в худшем случае SVM находит только 1 координату гиперплоскости на выборку.
Если данные хорошо структурированы (т. е. держит шаблоны довольно хорошо) может потребоваться только несколько опорных векторов - все остальные останутся позади них. Но текст-это очень, очень плохо структурированные данные. SVM делает все возможное, стараясь как можно лучше соответствовать образцу, и, таким образом, берет в качестве опорных векторов даже больше образцов, чем капель. С увеличением числа выборок эта "аномалия" уменьшается (появляются более незначительные выборки), но абсолютное число опорных векторов остается очень высоким.
классификация SVM линейна по числу опорных векторов (SVs). Количество SVs в худшем случае равно количеству обучающих выборок, поэтому 800/1000 еще не худший случай, но все еще довольно плохо.
опять же, 1000 учебных документов-это небольшой набор для обучения. Вы должны проверить, что происходит при масштабировании до 10000С и более документов. Если ситуация не улучшается, рассмотрите возможность использования линейных SVM, обученных с помощью LibLinear документ классификация; они масштабируются намного лучше (размер модели и время классификации линейны по количеству признаков и не зависят от количества обучающих выборок).
существует некоторая путаница между источниками. В учебнике ISLR 6th Ed, например, C описывается как" бюджет нарушения границ", из которого следует, что более высокий C позволит больше нарушений границ и больше опорных векторов. Но в реализациях svm в R и python параметр C реализуется как "штраф за нарушение", который является противоположным, и тогда вы заметите, что для более высоких значений C существует меньше опорных векторов.
Comments