2 ответов:
Я нахожу это в Java doc.
алгоритм сортировки представляет собой Двухшпиндельный Quicksort Владимир Ярославский, Джон Бентли, и Джошуа блох. Этот алгоритм предлагает o(n log (n)) производительность для многих наборов данных, которые вызывают другие quicksorts разлагаться с квадратичным критерием качества, и обычно быстрее, чем традиционные (один-pivot) реализации Quicksort.
затем я нахожу это в результатах поиска google. Thoery of быстрый алгоритм сортировки:
- выберите элемент, называемый pivot, из массива.
- переупорядочить массив так, чтобы все элементы, которые меньше, чем pivot, предшествовали pivot и все элементы больше опорного придет после него (равные значения могут идти любой путь.) После этого разбиения поворотный элемент находится в своем конечном положении.
- рекурсивно сортировать суб-массив меньших элементов и суб-массив больших элементы.
для сравнения, двойной поворот быстрая сортировка:
- для небольших массивов (длина
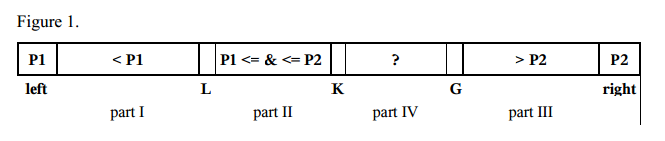
- выберите два поворотных элемента P1 и P2. Мы можем получить, например, первый элемент a [слева] как P1 и последний элемент a[справа] как P2.
- P1 должно быть меньше P2, в противном случае они меняются местами. Итак, есть следующие части:
- Часть I с индексами слева+1 к L-1 с элементами, которые меньше P1,
- Часть II с индексами от L до K-1 с элементами, которые больше или равны P1 и меньше или равны P2,
- Часть III с индексами от G+1 вправо-1 с элементами больше P2,
- Часть IV содержит остальные элементы, подлежащие исследованию с индексами от K до G.
- следующий элемент a[K] из детали IV сравнивается с двумя шарнирами P1 и P2, и помещается в соответствующую часть I, II или III.
- указатели L, K и G изменяются в соответствующих направлениях.
- шаги 4-5 повторяются при K ≤ G.
- поворотный элемент P1 заменяется последним элементом из части I, поворотный элемент P2 заменяется первым элементом из части III.
- шаги 1-7 повторяются рекурсивно для каждой части I, части II и Часть III.
для тех, кто заинтересован, посмотрите, как они реализовали этот алгоритм в Java:
Как указано в источнике:
"сортирует указанный диапазон массива, используя заданный фрагмент массива рабочей области, если это возможно для слияния
в алгоритм обеспечивает производительность O(n log(n)) во многих наборах данных, что приводит к снижению производительности других quicksorts до квадратичной и, как правило, быстрее, чем традиционные реализации Quicksort (one-pivot)."
Comments