Какой приоритет в реальном времени является самым высоким приоритетом в Linux
в диапазоне приоритетов процесса реального времени Linux от 1 до 99 мне неясно, какой из них является самым высоким приоритетом, 1 или 99.
В разделе 7.2.2 "понимание ядра Linux "(O'Reilly) говорится, что 1 является самым высоким приоритетом, что имеет смысл, учитывая, что обычные процессы имеют статические приоритеты от 100 до 139, причем 100 является самым высоким приоритетом:
" каждый процесс в реальном времени связан с приоритетом в реальном времени, который представляет собой значение в диапазоне от 1 (самый высокий
приоритет) до 99 (самый низкий приоритет). "
с другой стороны, man-страница sched_setscheduler (RHEL 6.1) утверждает, что 99 является самым высоким:
"процессы, запланированные в соответствии с одной из политик реального времени (SCHED_FIFO, SCHED_RR)
имеют значение sched_priority в диапазоне от 1 (низкий) до 99 (высокий)."
что является самым высоким приоритетом в реальном времени?
6 ответов:
Я сделал эксперимент, чтобы прибить это, следующим образом:
process1: RT priority = 40, CPU affinity = CPU 0. Этот процесс "вращается" в течение 10 секунд, поэтому он не позволит какому-либо процессу с более низким приоритетом работать на CPU 0.
process2: RT priority = 39, CPU affinity = CPU 0. Этот процесс печатает сообщение в stdout каждые 0,5 секунды, спящий между ними. Он печатает истекшее время с каждым сообщением.
Я запуск ядра 2.6.33 с патчем PREEMPT_RT.
чтобы запустить эксперимент, я запускаю process2 в одном окне (как root), а затем запускаю process1 (как root) в другом окне. В результате process1, по-видимому, вытесняет process2, не позволяя ему работать в течение полных 10 секунд.
во втором эксперименте я изменяю приоритет RT process2 на 41. В этом случае process2-это не вытеснен process1.
этот эксперимент показывает, что больше значение приоритета RT в sched_setscheduler () имеет более высокий приоритет. Это, по-видимому, противоречит тому, что Майкл Фукаракис указал из sched.ч, но на самом деле это не так. В sched.c в источнике ядра мы имеем:
static void __setscheduler(struct rq *rq, struct task_struct *p, int policy, int prio) { BUG_ON(p->se.on_rq); p->policy = policy; p->rt_priority = prio; p->normal_prio = normal_prio(p); /* we are holding p->pi_lock already */ p->prio = rt_mutex_getprio(p); if (rt_prio(p->prio)) p->sched_class = &rt_sched_class; else p->sched_class = &fair_sched_class; set_load_weight(p); }rt_mutex_getprio (p) делает следующее:
return task->normal_prio;в то время как normal_prio() делает следующее:
prio = MAX_RT_PRIO-1 - p->rt_priority; /* <===== notice! */ ... return prio;иными словами, у нас есть (мой собственный толкование):
p->prio = p->normal_prio = MAX_RT_PRIO - 1 - p->rt_priorityВау! Это сбивает с толку! Подводя итог:
при p - >prio меньшее значение вытесняет большее значение.
при p - > rt_priority большее значение вытесняет меньшее значение. Это приоритет в реальном времени, установленный с помощью sched_setscheduler ().
этот комментарий sched.h довольно определенно:
/* * Priority of a process goes from 0..MAX_PRIO-1, valid RT * priority is 0..MAX_RT_PRIO-1, and SCHED_NORMAL/SCHED_BATCH * tasks are in the range MAX_RT_PRIO..MAX_PRIO-1. Priority * values are inverted: lower p->prio value means higher priority. * * The MAX_USER_RT_PRIO value allows the actual maximum * RT priority to be separate from the value exported to * user-space. This allows kernel threads to set their * priority to a value higher than any user task. Note: * MAX_RT_PRIO must not be smaller than MAX_USER_RT_PRIO. */обратите внимание на эту часть:
значения приоритета инвертируются: ниже
p->prioзначение означает более высокий приоритет.
чтобы определить наивысший приоритет в реальном времени, который можно задать программно, используйте функцию sched_get_priority_max.
в Linux 2.6.32 вызов sched_get_priority_max(SCHED_FIFO) возвращает 99.
ваше предположение о том, что нормальные процессы имеют статические приоритеты от 100 до 139, в лучшем случае неустойчиво, а в худшем-неверно. Я имею в виду, что: set_scheduler только позволяет sched_priority быть 0 (что указывает на динамический приоритет планировщика) с SCHED_OTHER / SCHED_BATCH и SCHED_IDLE (true по состоянию на 2.6.16).
программно статические приоритеты 1-99 только для SCHED_RR и SCHED_FIFO
теперь вы можете увидеть приоритеты от 100-139 используется внутри a динамический планировщик howeve, r то, что ядро делает внутренне для управления динамическими приоритетами (включая переключение значения высокого и низкого приоритета, чтобы упростить сравнение или сортировку), должно быть непрозрачным для пользовательского пространства.
помните, что в SCHED_OTHER вы в основном заполняете процессы в той же очереди приоритетов.
идея состоит в том, чтобы упростить отладку ядра и избежать глупых ошибок вне границ.
таким образом, обоснование в переключении значения может как бы то ни было, разработчик ядра не хочет использовать математику, такую как 139-idx (на всякий случай idx > 139) ... лучше сделать математику с idx-100 и отменить концепцию низкого и высокого, потому что idx
также побочным эффектом является то, что с приятностью становится легче иметь дело. 100 - 100 хороший == 0; 101-100 хороший == 1; и т. д. проще. Он также рушится до отрицательных чисел (ничего общего со статическими приоритетами) 99 - 100 nice == -1 ...
- абсолютно, приоритет в реальном времени применим к политике RT FIFO и RR, которая варьируется от 0-99.
мы имеем 40 как отсчет non приоритета процесса реального времени для серии, других политик которая меняет от 0-39 не от 100 до 139. Это вы можете наблюдать, глядя на любой процесс в системе, который не является процессом реального времени. По умолчанию он будет иметь PR 20 и приятность 0. Если вы уменьшаете приятность процесса (обычно, ниже или отрицательное число меньше приятности, более голодный процесс), скажем от 0 до -1, вы заметите, что приоритет упадет до 19 из 20. Это просто говорит о том, что, если вы сделаете процесс более голодным или хотите получить немного больше внимания, уменьшив значение приятности PID, вы также получите снижение приоритета, таким образом, уменьшите номер приоритета выше приоритета.
Example: PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 2079 admin 10 -10 280m 31m 4032 S 9.6 0.0 21183:05 mgmtd [[email protected] ~]# renice -n -11 2079 2079: old priority -10, new priority -11 [[email protected] ~]# top -b | grep mgmtd 2079 admin 9 -11 280m 31m 4032 S 0.0 0.0 21183:05 mgmtd ^Cнадеюсь, что этот практический пример проясняет сомнения и может помочь исправить слова в неправильном источнике, если таковые имеются.
Короткий Ответ:
99 будет победителем в режиме реального времени приоритет.
PR-это приоритет. Чем ниже PR, тем выше будет приоритетность процесса.
PR рассчитывается следующим образом:
- для нормального протекания процессов: пр = 20 - никелевый (NI является хорошим и колеблется от 20 до 19)
- для процессов реального времени: PR = - 1-real_time_priority (real_time_priority колеблется от 1 до 99)
Ответ
есть 2 типа процессов,нормальный и реальном времени Для нормальных (и только для тех), Ницца применяется следующим образом:
хороший
шкала "приятности" идет от -20 до 19, тогда как -20 это самый высокий приоритет и 19 самый низкий приоритет. Уровень приоритета рассчитывается следующим образом:
PR = 20 + Ни
где NI-хороший уровень, а PR-уровень приоритета. Итак, как мы можем видеть, 20 на самом деле соответствует 0, а 19-39.
по умолчанию хорошее значение программы равно 0 бит пользователь root может обедать программы с указанным хорошим значением с помощью следующей команды:
nice -n <nice_value> ./myProgramВ Реальном Времени
мы могли бы пойти еще дальше. Хороший приоритет фактически используется для пользовательских программ. В то время как UNIX / LINUX общий приоритет имеет диапазон 140 значений, хорошее значение позволяет процессу сопоставить последнюю часть диапазона (от 100 до 139). Это уравнение оставляет недостижимыми значения от 0 до 99, которые будут соответствовать отрицательному уровню PR (от -100 до -1). Чтобы иметь доступ к этим значениям, процесс должен быть заявлен как "реальное время".
в среде LINUX существует 5 политик планирования, которые можно отобразить с помощью следующей команды:
chrt -mчто будет показать следующий список:
1. SCHED_OTHER the standard round-robin time-sharing policy 2. SCHED_BATCH for "batch" style execution of processes 3. SCHED_IDLE for running very low priority background jobs. 4. SCHED_FIFO a first-in, first-out policy 5. SCHED_RR a round-robin policyпроцессы планирования можно разделить на 2 группы, обычные политики планирования (от 1 до 3) и политики планирования в реальном времени (4 и 5). Процессы реального времени всегда будут иметь приоритет над обычными процессами. Процесс реального времени может быть вызван с помощью следующей команды (например, как объявить политику SCHED_RR):
chrt --rr <priority between 1-99> ./myProgramдля получения значения PR для процесса реального времени используется следующее уравнение применяется:
PR = -1-rt_prior
где rt_prior соответствует приоритету между 1 и 99. По этой причине процесс, который будет иметь более высокий приоритет над другими процессами будет называется с номером 99.
важно отметить, что для процессов реального времени, хорошее значение не используется.
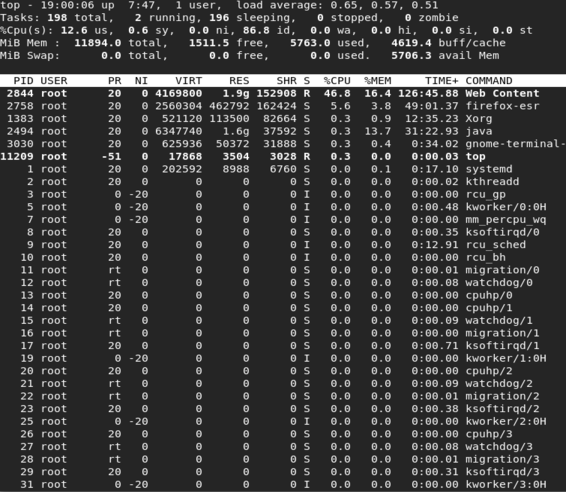
чтобы увидеть текущую "приятность" и PR-значение процесса, следующая команда может быть исполнено:
topкоторый показывает следующий вывод:
на рисунке показаны значения PR и NI. Хорошо отметить процесс со значением PR -51, которое соответствует значению в реальном времени. Есть также некоторые процессы, значение PR которых указано как "rt". Это значение фактически соответствует значению PR -100.
Comments