Почему одна длинная строка занимает больше места, чем множество маленьких строк?
вот некоторый код для DFA, реализованный в виде массива строк:
public class StringArray
{
private static final String[] stringArray = {
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
""
};
}
Я думал, что смогу сэкономить пространство, используя одну длинную строку вместо массива строк:
public class LongString
{
private static final String longString =
""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ ""
+ "";
}
как оказалось, я ошибался. Eclipse Kepler генерирует следующие файлы классов:
8516 Nov 28 22:42 StringArray.class
10005 Nov 28 22:42 LongString.class
почему второй класс даже больше, чем первый класс? Очень длинные строки несут какой-то штраф за пробел, о котором я не знаю?
2 ответов:
чтобы расширить ответ августа, я решил, что должен точно объяснить, как это компилируется и что занимает место на двоичном уровне.
для упрощения, я буду использовать следующий пример с более короткими строками. Важная часть заключается в том, что есть некоторые повторяющиеся строки.
есть три важные вещи, чтобы понять при компиляции этого кода.public class StringArray { private static final String[] stringArray = { "AAA", "AAB", "AAA", "AAC", "AAA" }; } public class LongString { private static final String longString = "AAA" + "AAB" + "AAA" + "AAC" + "AAA" ; }
- постоянная конкатенация строк выполняется во время компиляции. In дело в том, что это частный случай упрощения времени компиляции константных выражений. Вы можете найти точные правила для того, что является константным выражением в спецификации языка Java.
- инициализаторы скобок массива являются синтаксическим сахаром. Код эквивалентен созданию массива и назначению элементов по одному. (Обратите внимание, что это специфично для байт-кода Java. Dalvik (т. е. Android) имеет специальные инструкции стенографии для массива инициализация)
- встроенные инициализаторы-это синтаксический сахар. Код эквивалентен ручной инициализации полей в методе статического инициализатора.
Edit: одна незначительная деталь заключается в том, что в частном случае статических конечных полей, инициализированных в константное выражение inline, поле инициализируется с помощью атрибута ConstantValue вместо статического инициализатора, и все использования встроены. Так что в случае
LongString, #3 фактически приведет к другому байт-коду, но поскольку постоянные записи пула для строки одинаковы, размер файла, занимаемый строками, не изменится.сложил их вместе, и приведенный выше код эквивалентен следующему.
public class StringArray { private static final String[] stringArray; static { String[] temp = new String[5]; temp[0] = "AAA"; temp[1] = "AAB"; temp[2] = "AAA"; temp[3] = "AAC"; temp[4] = "AAA"; stringArray = temp; } } public class LongString { private static final String longString; static { longString = "AAAAABAAAAACAAA"; } }теперь это обессахаренный код по-прежнему показывает наличие повторяющихся строк в Примере массив несколько раз. Чтобы понять поведение размера файла класса, вы должны понять, для чего он компилируется.
когда вы доступ к постоянной строке, байт-код содержит инструкцию load constant (
ldcилиldc_w), который представляет собой однобайтовый код операции, за которым следует индекс в пул констант класса. Пул констант-это отдельный раздел файла класса, в котором хранится список констант. Очевидно, что компилятор будет хранить каждую константу только один раз.таким образом, байт-код для StringArray выглядит примерно так (удаляя несколько деталей, которые здесь не актуальны). Обратите внимание, что есть только 3 уникальные строки, хранящиеся в постоянном пуле. (На самом деле есть намного больше постоянных записей пула, относящихся к другим частям classfile, но они не важны здесь).
.class super StringArray .field static final private stringArray [Ljava/lang/String; .const [1] = String 'AAA' .const [2] = String 'AAB' .const [3] = String 'AAC' .method static <clinit> : ()V iconst_5 anewarray java/lang/String astore_0 aload_0 iconst_0 ldc [1] aastore aload_0 iconst_1 ldc [2] aastore aload_0 iconst_2 ldc [1] aastore aload_0 iconst_3 ldc [3] aastore aload_0 iconst_4 ldc [1] aastore aload_0 putstatic StringArray stringArray [Ljava/lang/String; return .end methodв то время как длинная строка выглядит примерно так
.class super LongString .field static final private longString Ljava/lang/String; .const [1] = String 'AAAAABAAAAACAAA' .method static <clinit> : ()V ldc [1] putstatic LongString longString Ljava/lang/String; return .end methodтаким образом, в первой версии повторяющиеся строки могут быть сохранены только один раз, тогда как во второй версии вся строка должна быть сохранена. Так что первая версия всегда лучше? Не так быстро. Он имеет преимущество не хранить дублированные строки, но, как вы, возможно, заметили, в инициализации массива есть большие накладные расходы на каждый элемент. Какой из них лучше зависит от того, сколько строк и сколько повторений у вас.
P. S. На двоичном уровне, постоянно кодируются с измененной кодировкой utf8. Результатом является то, что символы 1-127-это один байт каждый, но нулевые символы-это два байта. Таким образом, вы можете сэкономить место, компенсируя все 1.
у вас есть 18 дублировать строки в массиве (
StringArrayкласс). Поскольку каждая запись массива является отдельным строковым литералом, Для уникальный строки. Однако в вашем втором примере (LongStringclass), все дубликаты сохраняются и объединяются во время компиляции.это немного трудно смотреть на файл класса, который вы опубликовали, из-за размера строк. Я использовал более короткую версию, но она все еще имеет то же самое концепция:
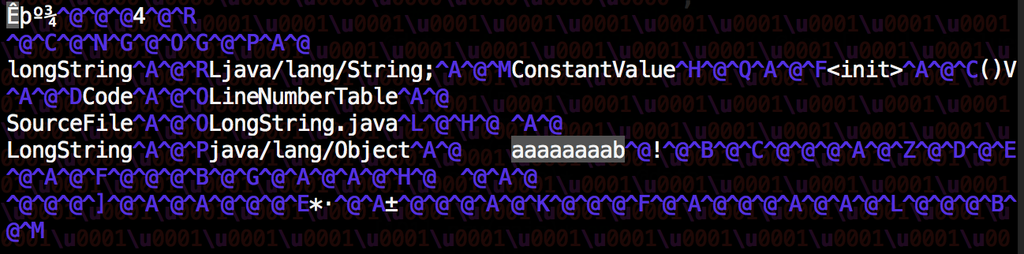
public class LongString { private static final String longString = "a" + "a" + "a" + "a" + "a" + "a" + "a" + "a" + "b"; }
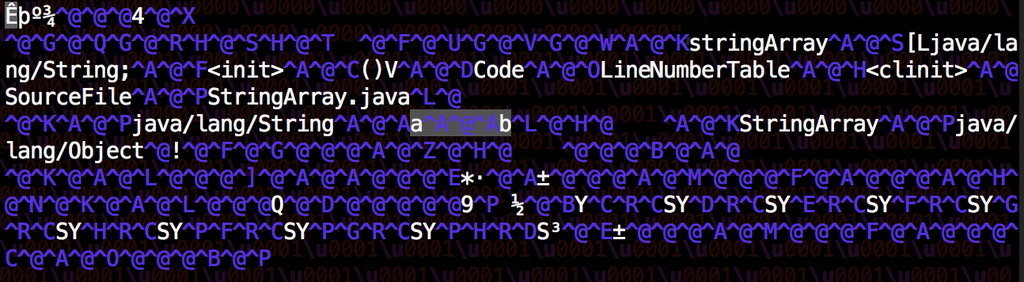
public class StringArray { private static final String[] stringArray = { "a", "a", "a", "a", "a", "a", "a", "a", "b" }; }если мы откроем файл класс
LongString.class, вы можете увидеть всю строку:
но если вы посмотрите на файл класс
StringArray.class, дубликаты были удалены:
пространство между
aиbи01 00 01, что означаетCONSTANT_Utf8_infoзапись длиной1.в вашем случае, повторное использование строк спасет 2,304 персонажей.
Comments